The topic I replaced Google Home and Alexa+ with a local voice assistant after realizing cloud… is currently the subject of lively discussion — readers and analysts are keeping a close eye on developments.
This is taking place in a dynamic environment: companies’ decisions and competitors’ reactions can quickly change the picture.
Smart home devices are already pretty handy thanks to their remote management tools, and voice assistants push their convenience to the next level. Google Home and Alexa+ are among the most common voice assistants in smart home setups, but despite their inherent benefits, I avoid them like the plague these days.
After dipping my feet into the self-hosted ecosystem, I’ve realized the privacy implications of relying on AI tools that hook up to some random company’s servers. With a little bit of tinkering, I managed to replicate the functionality of cloud-based voice assistants with an entirely local LLM pipeline – one that’s powered by my decade-old GPU and lets me control every gizmo I’ve paired with my Home Assistant server.
With the right apps and integrations, Home Assistant is an absolute powerhouse for tinkering enthusiasts
I often talk about the privacy-intrusive nature of surveillance camera setups that capture data from your home and store them on external servers in my articles, and voice-assistants that rely on the cloud are no better. Unless the voice assistant-powered device has a physical mute button, your AI-powered smart home control speakers will have their microphones turned on the whole time. And all it takes is one misheard wake word for them to record your conversations and send them to the manufacturer’s cloud.
Even if you leave out the plausible scenario where human reviewers may listen to your sampled audio recordings (which may include sensitive information), you’ve got the “services” that use your voice commands to build a digital profile of your usage habits and routines. At best, they’d turn this data into targeted ads, and at worst, they could end up selling it to third-party servers, making cloud assistants even more of a privacy nightmare if you’ve got as many smart devices scattered across your home as I do.
But for folks who aren’t too concerned about privacy issues, you’ve got the disconnection problem to contend with. Let’s say you managed to lose connection to the company servers (be it from Internet drops or issues on the cloud side). Welp, your entire voice control setup will go down the drain until the connection gets restored. And considering the AWS outage of October 2025, that’s a pretty valid fear.
There’s no point in relying on AI tools when my local LLMs can handle everything
Starting with the core of my voice assistant pipeline, I’ve got my aged GTX 1080 powering the models responsible for tackling the main inference needs. If you’re wondering how a 10-year-old GPU can run LLMs that don’t devolve into hallucination-riddled loops, it’s all thanks to the MoE offloading functionality of llama.cpp. Rather than forcing my GPU to run entire models, adding the –n-cpu-moe flag lets me offload the bulky experts on the underlying CPU and RAM. But since the main router mechanism stays on the graphics card, I still get decently fast token generation speeds for my smart home pipeline.
For reference, I’ve got Gemma-4-26B-A4B running at 14 tokens/second, and while it’s pretty decent for typical smart home tasks, it can feel a bit slow when I just want simple sensor statistics. So, I’ve started using gpt-oss-20b, which provides better response times without misinterpreting my commands.
Unfortunately, the Ollama extension (which I used before transitioning to llama.cpp) doesn’t work with models hosted via llama-server. But as you’d expect from the Home Assistant community, third-party devs have created some amazing integrations for bringing OpenAI-compatible APIs to HASS. The Extended OpenAI Conversation integration is really useful, but I stick to Home Agent due to its extensive customization options. Thanks to the Home Assistant Community Store, configuring them is fairly straightforward (though I had to spend a little more time tweaking all the Home Agent settings to my liking).
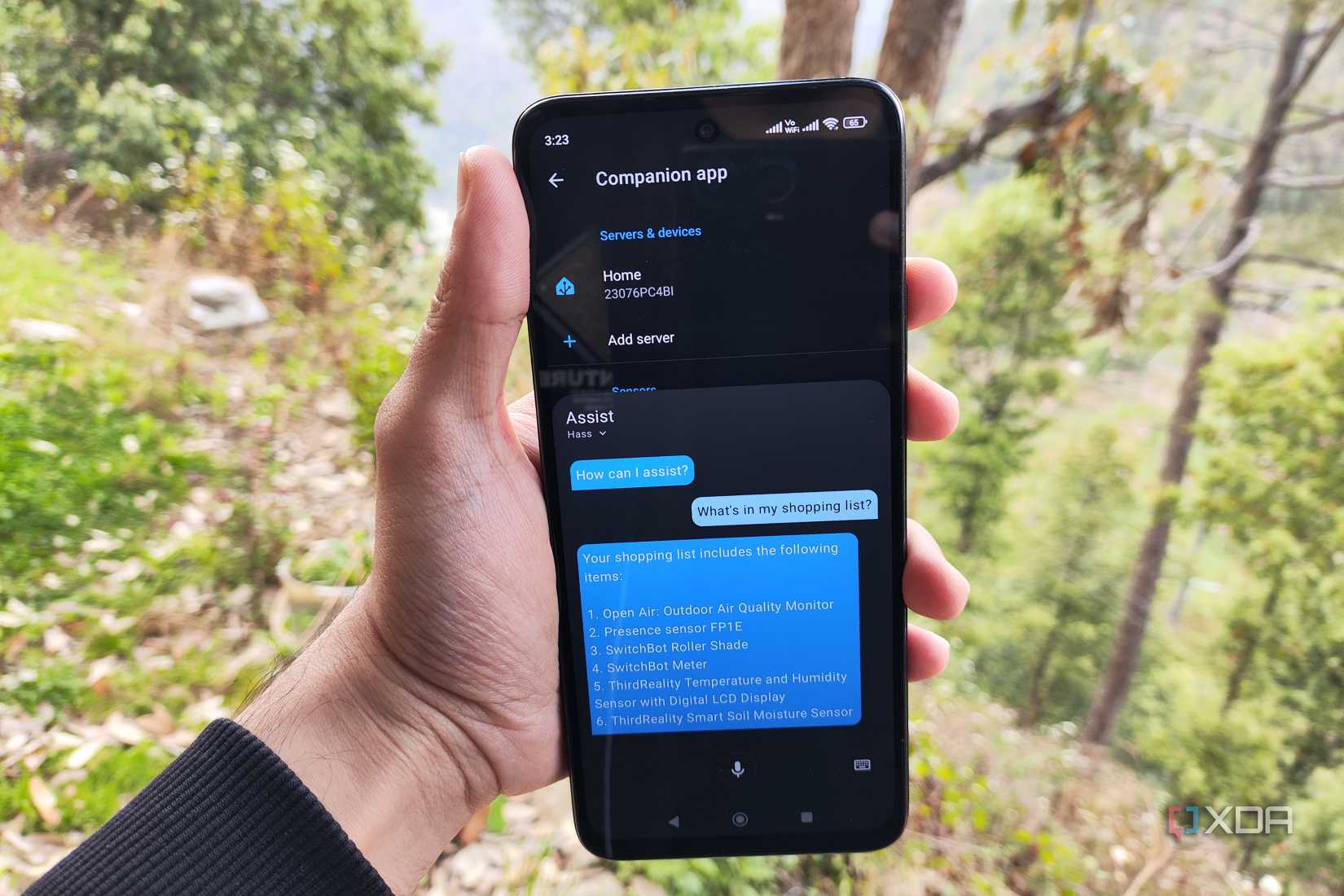
Although my llama.cpp LXC is responsible for the bulky conversation model that handles the inference tasks, I still need other components for my voice assistant. First, I needed a way to configure wake word detection, which is essentially a trigger phrase that activates my AI models. Fortunately, the Home Assistant Companion app supports wake word detection (and processing) for Android devices, so I don’t need to build a manual hot word workflow from a microhone and ESP32 microcontrollers.
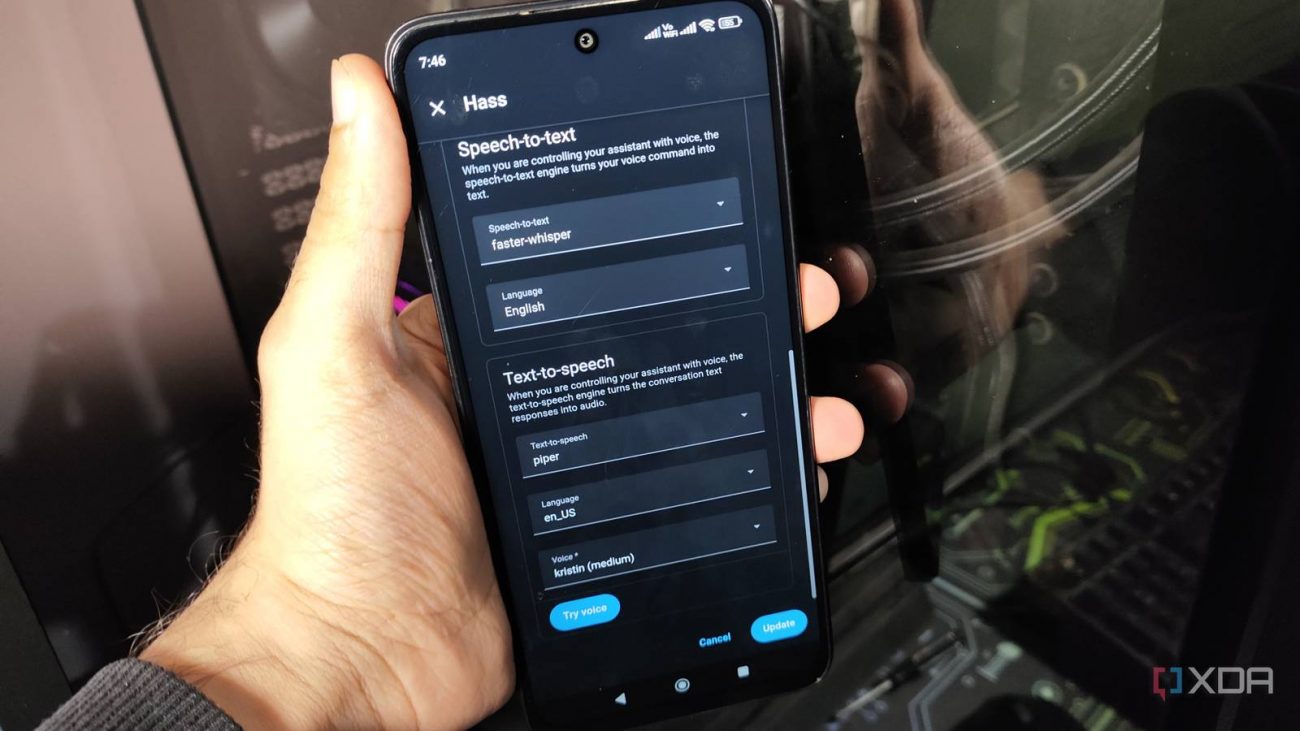
I’ve already configured an old tablet as a Home Assistant dashboard, so I simply enabled the wake word functionality (with “Okay, Nabu” being the trigger word) within the HASS Companion app settings. Then, I headed to the App Store on my Home Assistant server and configured Piper as the text-to-speech hub. But I also needed a speech-to-text utility, and although the Speech-to-Phrase app is decent, I prefer using Whisper for my STT needs.
Besides the voice assistant, I sometimes use the Home Assistant MCP server with VS Code when I want to design complex automations without constantly switching through waves of menus on the HASS web UI. I’ve also paired an MCP server with my Nextcloud container, and I often use it to manage my notes, calendar events, and academic documents using simple text prompts.