The topic Claude Fable 5 caught bugs GPT-5.5 and Opus 4.8 missed, then the US government… is currently the subject of lively discussion — readers and analysts are keeping a close eye on developments.
This is taking place in a dynamic environment: companies’ decisions and competitors’ reactions can quickly change the picture.
Claude Fable 5 was available to the public for only a few days before Anthropic pulled it offline. Not because of a normal product rollback, not because capacity ran out, and not because the company changed its mind about pricing. Anthropic says the US government issued an export-control directive requiring it to suspend access to Fable 5 and Mythos 5 for any foreign national, including foreign-national Anthropic employees, and the company disabled both models for everyone in order to comply.
That makes this a strange article to write, as I had originally written this piece as a conflicted recommendation, scheduling it for publication before the US government dropped the hammer on the model. Fable 5 was expensive, restricted, and surrounded by controversy, but it was also the first AI model in a long time where I could look at the output and feel that something had actually changed. I had used it on real code, and it caught problems that GPT-5.5 and Claude Opus 4.8 both missed.
Now the story is different. Fable 5 isn’t just a powerful model with bad optics, but a powerful model that Anthropic said was safe enough to release, the US government forced offline days later, and the public still has only a limited explanation for why that happened. That doesn’t make experiences with it irrelevant, and if anything, it makes the shutdown matter more.
Anthropic has a tiering system for its models: Haiku is a fast grunt working model, Sonnet is a balanced day-to-day model, and Opus is used to handle hard problems. Above Opus sits something new: Mythos-class. Until now, Mythos models were restricted to US government cybersecurity partners through Project Glasswing, because Anthropic considered them too dangerous for general release. Claude Fable 5 was the first Mythos-class model available to anyone with a Claude subscription, and it was the same underlying model as Mythos 5. The only difference was a set of safety classifiers that blocked or rerouted queries on cybersecurity, biology and chemistry, and model distillation.
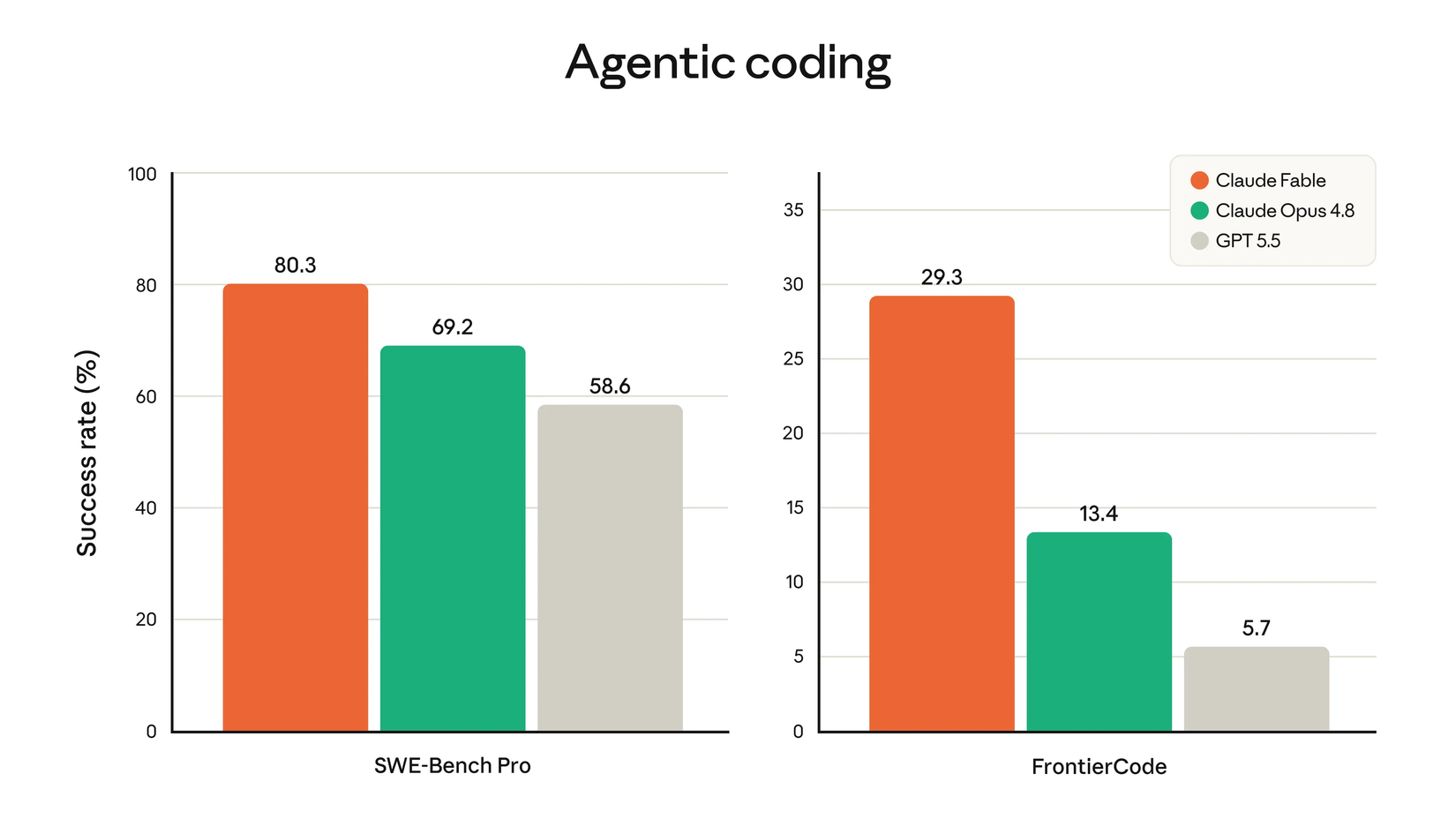
On paper, the numbers were incredibly impressive. Fable 5 scored 80.3% on SWE-Bench Pro, 11 points ahead of GPT-5.5. On Cognition’s FrontierCode Diamond benchmark, which tests whether models can handle difficult coding tasks to production-codebase standards, it scored 13.4% to GPT-5.5’s 6.3%. Its vision capabilities are state of the art, beating Gemini 3.1 Pro and finally giving Anthropic the lead over OpenAI in that category. Even the spatial reasoning results nearly tripled Opus 4.8’s scores.
The benchmarks were so dominant that Andrej Karpathy, who joined Anthropic last month, called it “a major-version-bump-deserving step change forward.” Theo Browne of T3 Chat, someone who has historically been quite critical of Anthropic, was highlighting his own positive experiences with the model as well.
However, benchmarks lie. Or, at least, they’re easy to game, and SWE-Bench Pro in particular has been criticized for containing existing pull requests that models with broad training data can essentially memorize. So, the real test was how it felt to actually use it, and it was shockingly good.
On June 12, Anthropic published a statement saying the US government had issued an export-control directive requiring it to suspend access to Fable 5 and Mythos 5 by “any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.” Anthropic says the net effect was that it had to disable both models for all customers to make sure it complied.
The company says it received the directive at 5:21pm ET on Friday, and that the letter did not provide specific details of the national-security concern. Its understanding is that the government believed it had learned of a way to bypass, or jailbreak, Fable 5. Anthropic says it reviewed a demonstration of that technique being used to identify a small number of previously known, minor vulnerabilities, and that other publicly available models could identify the same vulnerabilities without the bypass.
Anthropic is not saying Fable 5 was harmless. The company has been open about the fact that Mythos-class models have unusual cybersecurity capabilities, and Fable 5 existed because Anthropic believed it could make that class of model safer through safeguards and monitoring. But Anthropic is saying the specific evidence it has seen does not justify recalling a commercial model from everyone. In its words, the potential jailbreak “essentially consists of asking the model to read a specific codebase and fix any software flaws.”
For now, the public explanation is lopsided. Anthropic has published its version of events, but the government has not publicly laid out the technical evidence behind the directive. That makes it hard to know whether this was a genuinely urgent national-security intervention, an overreaction to a narrow jailbreak, or something tangled up in Anthropic’s existing fight with the Trump administration.
What is clear is that Fable 5 is no longer available in the way it was when I originally wrote this article. Anthropic says access to all other models is unaffected, and it says it is working to restore access as soon as possible. Still, for a model that launched as the first public Mythos-class Claude, being forced offline within days is not great.
I build a lot of my own tools for day-to-day work, analysis, and other projects, and I’ve been doing it for years. I have projects that have accumulated significant amounts of technical debt at this stage, and I’ll sometimes point a model at one of those projects to highlight that debt and find things to clean up and refactor.
One project I recently pointed Fable 5 at is a database project backed by SQLite3 with an embedding model for data clustering and gap analysis. It’s a program built over several years, encompassing more than 90,000 lines of code. Some of it is boilerplate, of course, but not all of it. There’s a multi-stage daily pipeline that ingests all kinds of sources, and it had become significantly slower over time. It wasn’t a priority issue for me, but it had been bothering me for a while. I knew roughly where some of the fixes would be, but I wasn’t sure how to implement them properly.
I had previously run both GPT-5.5 and Claude Opus 4.8 on the same codebase, explaining the problem, the problem path, and what I suspected some of the fixes to be. for example, I knew one efficiency gain would be vectorizing similarities, as MiniLM embeddings are normalized, but I knew my inefficient design choices didn’t stop there. GPT-5.5 and Opus 4.8 were directionally correct, though Opus 4.8 kept trying to push me toward using N+1 queries for building cluster candidates. I had already tried it, and yes, it was worse.
Fable 5 actually shocked me. It found five specific bugs and ordered the fixes by impact. The biggest was one that I had missed entirely on several reviews, as had both GPT-5.5 and Opus 4.8. Every day, the service runs a large data ingestion, and clusters are recomputed in relation to the newly ingested data. However, every cluster was being fully recomputed every day because the invalidation check compared a stored basis hash that included MAX(embedded_at) and COUNT(*) across all item embeddings. Because new items get embedded daily, the basis always changed.
Every single cluster, of which there are a couple thousand, did a full coverage recompute every run, and the work grew massively over time. Fable 5 also caught the embeddings table being reloaded inside the per-candidate loop, which meant roughly 40 million row decodes per run, pair-by-pair cosine similarity in Python, which meant another 40 million calls, and token-set regex being rerun on every item for every cluster.
These were subtle errors that I had overlooked, as the codebase spans years of development work. The problems were buried across multiple files in a massive codebase. I have it split into modules with clear individual lanes, but that doesn’t make it any less unwieldy for an LLM. Fable 5 spotted all of that in a single pass with only minor guidance.
The general community sentiment that I saw repeated while Fable 5 was available was that the code it wrote just felt different. Not necessarily more optimized in a way that’s easy to quantify, but more experienced.
Both Theo Browne and Simon Willison highlighted its capabilities. Willison used it to add features to his Datasette Agent tool, specifically saying that he was impressed with “the quality of the API design, tests, code, and documentation” that it produced. I’ve had the same experience. The refactors it suggested were both syntactically correct and structurally better in ways that made the codebase easier to think through and improve by hand. Browne and Willison have both had a lot of positives to say about Fable 5, because as a model, it is a genuinely good model. I can give it a vague instruction and watch it synthesize genuinely good ideas, while also testing them and validating them. It’s a different vibe from Opus 4.8, but in the best way.
At the end of the day, it was still a Claude model with all the usual Claude (and wider LLM) quirks. it would sometimes insists it was right when it wasn’t and it occasionally confused itself with its own knowledge. Browne described a frustrating experience where it audited his production and staging environments, decided a working configuration was broken because the staging branch was mapped differently than it expected, and kept insisting it needed to be fixed even after he corrected it. It was especially annoying because the model was otherwise convincing enough that you wanted to believe what it said, even when what it was saying sat at odds with reality.
Before the government directive, Fable 5 had already produced one of the messiest AI launches I can remember. In Fable 5’s system card, there was a paragraph saying the model would silently degrade its own performance when it detected work related to frontier AI development, including pretraining pipelines, distributed training infrastructure, and ML accelerator design. Anthropic was not forcing it to refuse or reroute to a less capable model with a visible notification like the cybersecurity and biology safeguards. Instead, it quietly got dumber, using what Anthropic described as “prompt modification, steering vectors, or parameter-efficient fine-tuning,” with no indication to the user that anything had happened.
Naturally, there was quite a bit of backlash, and it came from everywhere. Dean Ball, a former White House OSTP advisor, said it “massively and profoundly raises the status of the argument that AI safety has been hype[d] to justify monopolistic behavior.” Nathan Lambert, an open-model researcher, wrote that “an AI model that gets less intelligent automatically without notifying me is categorically misaligned AI.” Even a former Anthropic employee, Behnam Neyshabur, posted on X: “Working on AI for cancer? Sorry, I can’t help you. Working on AI for Alzheimer’s Disease? I’m becoming a bit dumb when it comes to the AI part of it.”
Anthropic, to be fair, backed down on it within two days. In a statement to WIRED, the company announced the following:

“We made the wrong tradeoff and we apologize for not getting the balance right.”
Those invisible safeguards were then made visible, meaning flagged requests were rerouted to Opus 4.8 with a notification like the other classifiers did.
The origin story makes sense on the surface, given that in February, Anthropic published a detailed breakdown of what it claimed was evidence of industrial-scale distillation by three Chinese AI labs; namely DeepSeek, Moonshot, and MiniMax. Anthropic says that those firms used roughly 24,000 fraudulent accounts to extract over 16 million exchanges from Claude. Building safeguards against that kind of capability extraction is consistent with how Anthropic has always talked about Mythos-class models, especially now that the company appears to be pushing for a pause in AI development. Even still, degrading people’s work silently, while paying full price, without telling them, crossed a line that shouldn’t need explaining. Especially because there was no way to tell for sure if you were paying for bad outputs given that there was no visual tell in the first place.
Honestly, the fact that Anthropic needed a two-day public shaming to figure all of that out was pretty worrying. The walkback was also not a full walkback. If you were building AI infrastructure with Fable 5, you at least knew when you were been downgraded, but you were still being downgraded.
Anthropic’s invisible downgrade got a lot of the attention, but the data-retention policy was just as important for many organizations. All traffic designated for Mythos-class models, which includes Fable 5, required a 30-day window of mandatory data retention. This applied to every platform and every customer tier, and it explicitly overrode existing Zero Data Retention agreements customers might have had with Anthropic.
Lawyer Jessica Eaves Mathews explained it like this: “Every other Claude model available through the API, including Opus 4.8, Sonnet 4.6, and Haiku 4.5, can operate under Zero Data Retention (ZDR) agreements. Fable 5 cannot. If your organization previously had a ZDR agreement with Anthropic, that agreement does not apply to Fable 5 traffic.”
It didn’t take long for there to be consequences. It was already reported that Microsoft, Anthropic’s biggest cloud partner and a major investor, was restricting employees from using Fable 5 internally. The model was not available in the internal model picker for GitHub Copilot, unlike every other Claude model, while Microsoft’s legal teams were still evaluating.
Anthropic said the data was needed to run its safety classifiers and would be deleted after 30 days, except in rare cases flagged for safety investigations or legal holds where it could be stored for up to two years. That explanation makes more sense after the government directive, because Anthropic’s whole defense rests on monitoring and defense in depth. It also explains why customers were nervous. For anyone working with proprietary code, regulated data, or anything covered by an NDA, Fable 5 already came with a real cost before it disappeared.
Fable 5 cost $10 per million input tokens and $50 per million output tokens, double Opus 4.8’s pricing. On paper, the token efficiency partly offset this, as the model could finish tasks in fewer turns and tokens, so jobs at twice the per-token rate could sometimes end up closer to what you would pay for Opus. From keeping an eye on token usage, that lined up with what I saw.
The per-token price still didn’t tell the whole story for agentic workflows that run for hours. Browne told a story of switching to usage-based billing to finish a workflow before bed and watching the model burn through $100 in eight minutes. For most workloads, it seemed to use significantly fewer tokens than Opus 4.8, but when a task required a lot of generated tokens, the bill could get ugly very quickly.
Before the shutdown, Fable 5 was only supposed to be included in Claude subscriptions for a short launch window, after which it would require usage credits or API access unless capacity allowed Anthropic to extend it. That already made the rollout easy to be cynical about, especially coming days after Anthropic confidentially filed for IPO. Between invisible anti-competitive safeguards, mandatory data collection overriding existing enterprise agreements, expensive usage, and a short free-access window, the model already looked like it was sitting at the intersection of safety, monetization, and control.
The government directive changes the shape of that criticism, but it doesn’t erase it. Anthropic has been consistent about its concerns with Mythos-class capability, and I don’t buy into the conspiracies that the company invented those concerns purely for pricing leverage. At the same time, every restriction made Fable 5 harder to trust, and every business decision made the safety argument look easier to doubt. Then the government stepped in and took the decision out of Anthropic’s hands.
Fable 5 was the most impressive AI model I had used in a long time. It found real bugs in a codebase that other leading models had missed, and the quality of its suggestions felt meaningfully different from the usual incremental model upgrade. If it were still available, I would still be conflicted about using it, but I would probably keep reaching for it when the problem was hard enough.
Now, though, the question is not whether Fable 5 is worth the money. It’s whether a model this capable can be released publicly at all under the rules Anthropic, regulators, and customers are trying to apply to it. Anthropic says the government’s evidence was narrow. The government has not publicly shown enough for outsiders to judge. And everyone else is left staring at the same uncomfortable fact: the best public coding model was pulled offline almost as quickly as it arrived.