The topic Local LLMs perform so much better when you teach them to ask before they answer is currently the subject of lively discussion — readers and analysts are keeping a close eye on developments.
This is taking place in a dynamic environment: companies’ decisions and competitors’ reactions can quickly change the picture.
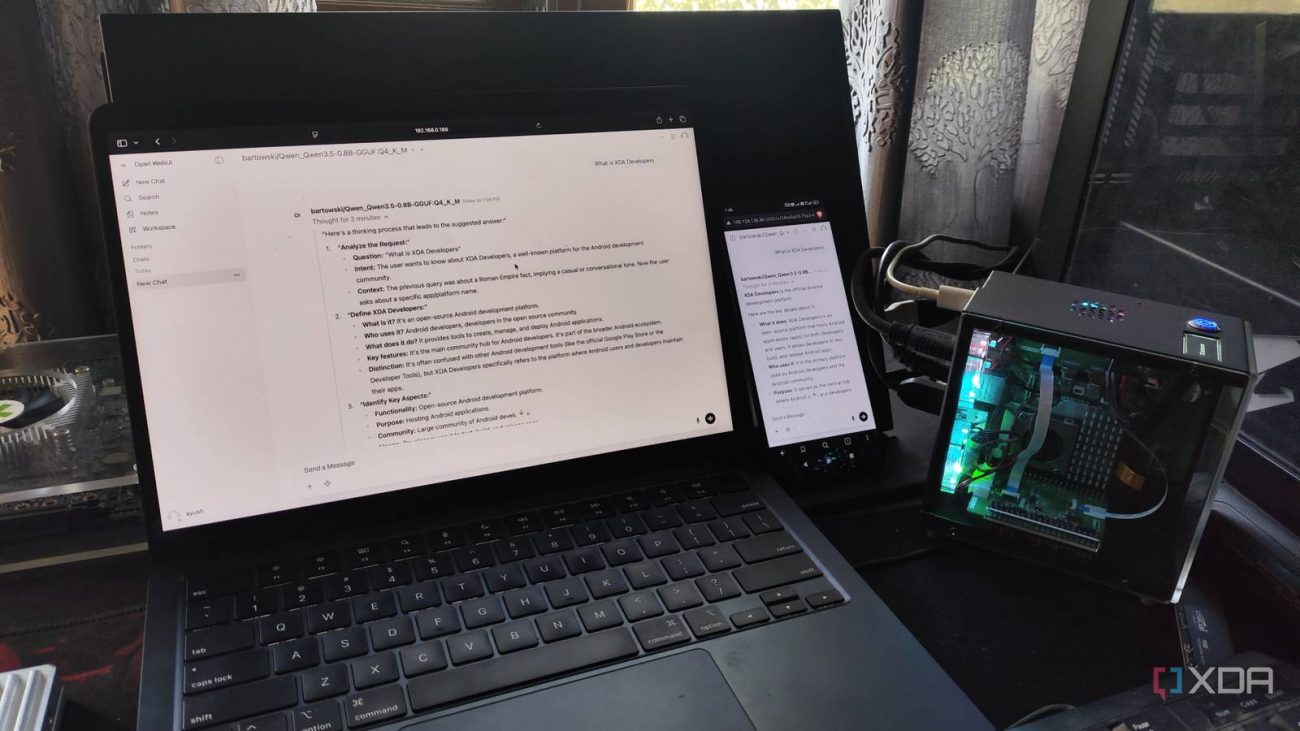
Prompting an LLM requires a different approach than typing a search query into Google, yet it’s common for people to treat them the same. The process often goes something like this: type a sentence, get a response, then ask refining questions or supply follow-up context to guide AI toward the information you’re after. If you’re only asking for a simple answer, then simple questions usually work fine. But for tasks involving deeper context or multiple steps, you’re normally two or three exchanges deep before the model begins to understand what you actually wanted.
On local LLMs specifically, which already lag behind cloud models, starting an interaction off with an ambiguous prompt puts you in a hole that’s hard to dig your way out of. You can try writing clearer prompts (always a good practice), but there’s still a chance that the LLM can’t guess exactly what you mean. What fixed this for me was instructing local models to ask clarifying questions before attempting any non-trivial task. Now, instead of me doing any guesswork, AI lets me know if any part of my prompt needs additional clarification. Tasks that used to take several extra exchanges only take one or two now.
Who needs OpenAI when your home lab can do the thinking for you?
Cloud models like Claude and ChatGPT are great at reading between the lines and inferring the underlying intent from a user’s prompts. Even vague questions receive a serviceable answer surprisingly often. But that only works because cloud models have the unique advantage of being trained on enormous datasets, and the millions of questions they’re asked every day also contribute to the training data. Local models don’t have that luxury.
In my experience with Llama and Qwen models through Ollama, any ambiguity in my prompt leads to inconsistent interpretations. A simple prompt like “write a summary of this document” doesn’t give the model any information about the tone or length you’re expecting, or what kind of audience the summary is for, or what format it should be in. The model needs to make all those assumptions before proceeding. The chances of the result coming back exactly the way you expect it are slim. If it gives you back a paragraph when you wanted bullet points, that’s more back and forth to get things right, which grows annoying.
The custom instructions are best placed inside of a Modelfile, so that it can persist across different sessions. Otherwise, you’re stuck copying and pasting the instructions into every new chat. Here’s what my Modelfile looks like:
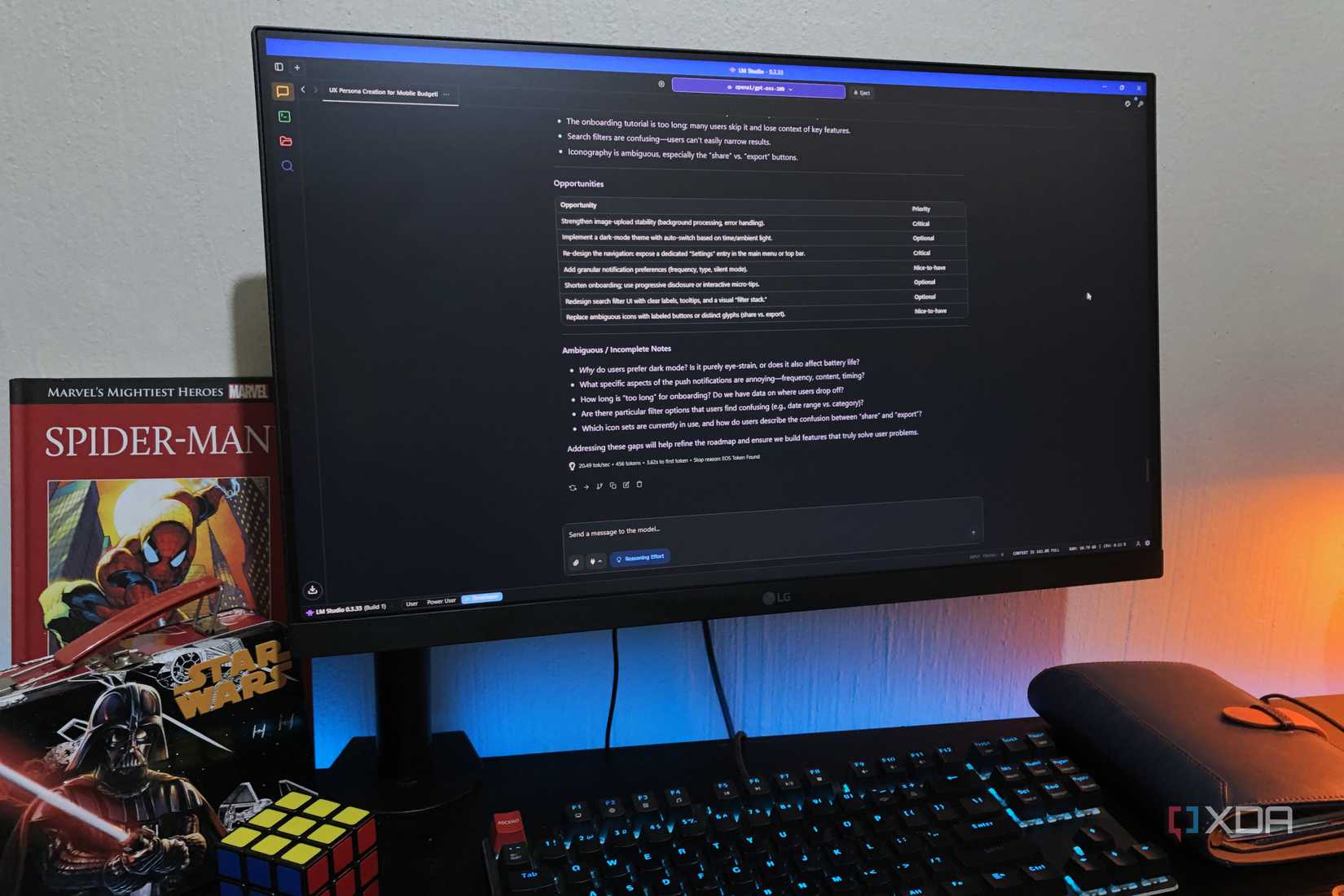
Simple enough, but it actually took me a few iterations to arrive at the current instruction set. Bits like “up to three” are important, because I’ve had earlier versions of my custom instructions work against me in the past, with some models asking too many follow-up questions. “Targeted” is also an essential part. Before adding it, the model was asking vague questions instead of specific things it actually needs for completing its task.
To integrate those custom instructions into Ollama, you can paste them into a new file named “Modelfile” (no extension). Once that file is saved, run ollama create my-assistant -f Modelfile. After that, your new model with the custom instructions is ready to go with ollama run my-assistant, or from the model dropdown selector if you’re using the GUI.
Being asked to answer multiple clarifying questions on most prompts may sound like it’d be more likely to slow tasks down than speed them up. For cloud models, that assumption is probably true, because they’re already good enough at guessing your intent on the first try. For my local models, answering additional questions is a nice band-aid to the issue, and it’s worked out as a net positive on the time savings. I’ve always found an unhelpful response more frustrating than a few follow-up questions, anyway.
There’s also a positive side effect from all this that I hadn’t originally intended. Answering clarifying questions often forces me to think about the task more, and hone in on exactly what I want to accomplish with it. There have been a few times when the model’s questions made me realize I hadn’t fully thought something through in the first place. It makes the model feel more like an assistant that helps me think through the process.
If you’re tired of getting unhelpful responses from your local models, it could be that they simply don’t have enough information to do the job right. Teaching it to ask for clarification is a one-time fix that only takes a few minutes, and you start reaping the benefits on your very next prompt.