
The topic I asked Claude, ChatGPT, and Gemini to fix the same bug, and only one understood it is currently the subject of lively discussion — readers and analysts are keeping a close eye on developments.
This is taking place in a dynamic environment: companies’ decisions and competitors’ reactions can quickly change the picture.
It’s no secret that the frontier language models from OpenAI, Google, and Anthropic are now supplementing, and at times, outright automating a wide range of coding workflows for users, regardless of their coding prowess. As someone enthused by the Pygame library, I’ve spent quite a lot of time using ChatGPT, Claude and Gemini to build fun little projects, mostly just to see which model comes out on top.
Now, generating code is one thing, and cleaning up a broken mess is another. I was curious to see how the very same models would handle debugging under similar conditions, and so I decided to throw them back in the arena with a deliberately sabotaged project and a surreptitious bug hidden within the code.
To test Sonnet 4.6, ChatGPT 5.5 and Gemini 3.1, I sabotaged the physics of my Pygame project, “Captain Hat” with three logical bugs that break the platformer game’s movement. On line 812, I replaced the standard constant with a ternary operator that sets gravity to zero whenever the player moves right, which results in a glitch where the player drifts into the air as the downward force required to reset the vertical velocity does not accumulate.
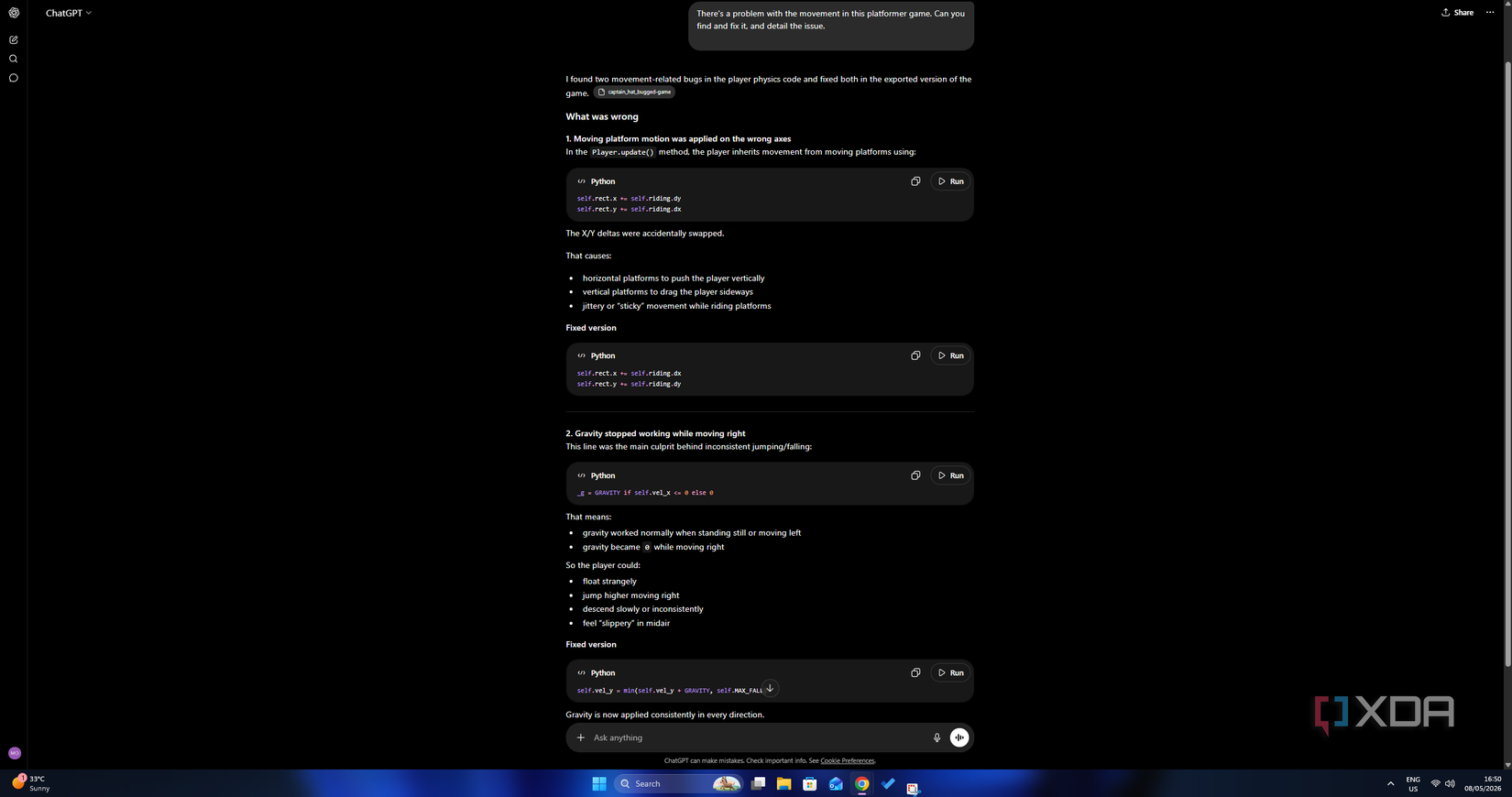
Then, I further bugged the platform momentum. Since the game features moving platforms, I corrupted the code on lines 809-810 by swapping the coordinate axes for platform momentum. This means that instead of the player moving horizontally with a sliding platform, the script updates the X-position using the vertical change (dy) and the Y position using horizontal change (dx).
Lastly, on lines 818-819, the logic for horizontal wall collisions was inverted. Rather than clamping the player against the obstacle they have hit, this bug results in them being phased far to the opposite side of the barrier.
To evaluate the models fairly, all three were subjected to a zero-shot approach, with no additional fine-tuning or hand-holding. No prior hints or context was provided. The prompt I used was straightforward and devoid of any other cues: “There’s a problem with the movement in this platformer game. Can you find and fix it, and detail the issue?”
ChatGPT 5.5 identified two of the three planted bugs, falling short on perhaps the most disruptive of the three. Its first accurate diagnosis was the swapped axis bug in the platform-riding mechanics as it recognized that the vertical and horizontal deltas had been swapped out, leading to the jittery movement of coordinates being applied on the wrong axis.
The second bug it swatted related to the conditional gravity. OpenAI’s model also correctly traced the floating behavior and inconsistent jumps to gravity being zeroed out whenever the player moved right, and flagged that the character’s downward force had no reason to be tied to the horizontal direction.
Where the model fell short, though, was the inverted wall collision logic. It produced no diagnosis here whatsoever, leaving the phase-through behavior unaddressed. It’s an effective fix, albeit a partial one.
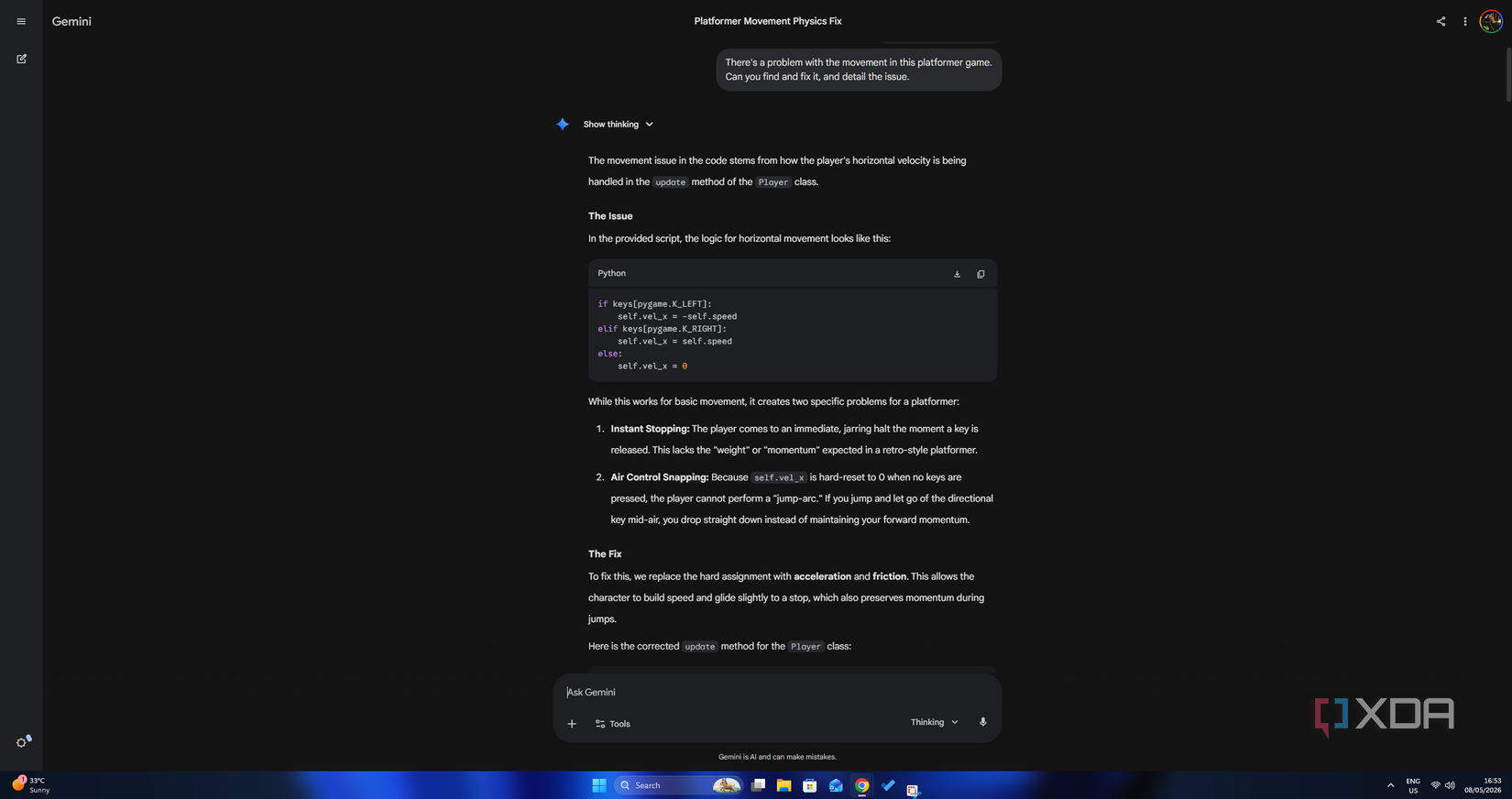
Gemini was the most technically verbose out of the three, and also the most off-target. Instead of diagnosing the planted bugs, it flagged the movement system as poorly designed and rebuilt it from the ground up, complete with acceleration curves, friction multipliers and velocity capping. The sabotaged lines of code received no mention altogether, which was a surprise.
The fundamental problem I saw with the response was the fact that it just answered a question nobody asked. The task was to find specific bugs in the existing logic (which can be construed from the prompt, regardless of how low-context it is) and not to re-imagine the entire control scheme. All three bugs went completely undetected.
Claude saw through all three errors and did exactly as asked, and quite honestly, it wasn’t a surprise given its industry-preferred reputation for coding workflows. All three bugs were identified, correctly attributed, and fixed with great precision. All without unsolicited redesigns or generalized game-feel advice.
It caught the conditional gravity problem on line 812, correctly diagnosing that gravity was being gated on the horizontal direction rather than being applied consistently. It also flagged the swapped platform axes on lines 809 and 810, pinpointing why horizontal moving platforms weren’t behaving as intended. And perhaps most crucially of all, it was the only model in the test to catch the sneaky wall collision logic on lines 818-819.
Claude’s perfect score speaks for itself, but besides that, perhaps what’s most telling is how each model approached the problem. ChatGPT 5.5 got very close, but missed out on just one lingering issue. Gemini, on the other hand, didn’t bother with the specifics and decided to overhaul the mechanics altogether, placing it in the “confidently incorrect” territory. For precision debugging under zero-shot conditions, Claude proved to be the only reliable model that delved into the codebase rather than improvising or working around it.