The topic I tested Claude’s two biggest competitors because of its usage limits, and one… is currently the subject of lively discussion — readers and analysts are keeping a close eye on developments.
This is taking place in a dynamic environment: companies’ decisions and competitors’ reactions can quickly change the picture.
Claude is still the best AI coding tool I’ve tested out, but its usage limits have become hard to trust. The tiers keep changing, the allowance seems to drain faster than it used to, and if you rely on it for real work, that uncertainty gets annoying fast. So I went looking for alternatives, tested Claude’s two biggest competitors on the same coding task, and one of them banned my account before I could finish.
Because of those limits, I did what any mildly annoyed developer would do and looked at what else was out there. MiniMax M2.7 and Z.ai’s GLM-5.1 are the two names that come up most often when people talk about cheap Claude alternatives, both pitched as drop-in replacements for Claude Code-compatible harnesses. I set both up in the Pi harness, ran the same coding test I’d already used against Claude Opus 4.6 as my baseline, and threw Qwen3-Coder-Next into the mix on my ThinkStation PGX as a local reference point. I used Opus 4.6 here because, at the time of testing, Opus 4.7 hadn’t been released yet.
What I found surprised me in both directions. One of them is genuinely a solid Claude alternative for most developers. The other one banned my account with zero warning.
I wanted something that would stress the things that people actually use Claude for, not just a regular old benchmark. I asked each model to build a small Python CLI tool called “logsift.” The premise is simple: it reads a timestamp-prefixed log file, has three subcommands (tail, grep, and stats), supports a –since flag for time windows, renders a simple ASCII bar chart for the stats command, and ships as a proper installable package with pyproject.toml, a README, and pytest tests. Standard library only.
It’s not a hard task, but it’s a realistic one. It forces the model to plan a multi-file package, handle edge cases like malformed lines, write tests that actually test something, and render something visual. Plenty of places to cut corners, but also plenty of places for a model to show off.
I ran every model once on the same task with the same prompt, though Qwen3-Coder-Next had Context7 available for documentation lookups to better reflect how people actually use local coding models, especially since the cloud models already have built-in web and tool access. Aside from that, none of the models had any follow-ups or any corrections. I wanted to see what each one produced on the first shot. Each run took roughly three minutes.
After that, I went through the code, scoring each model’s spec compliance, code quality, test honesty, and whether the ASCII chart actually rendered properly.
MiniMax M2.7 did well. Not Opus-well, but well enough that I’d happily use it for everyday coding if price were my main constraint. It produced a clean, 152-line implementation with 137 lines of real tests. The ASCII chart rendered proportionally across 24 hourly buckets. Malformed lines were skipped cleanly. The tests actually tested the behavior of the application created through both core functions and the CLI.
Unfortunately, it wasn’t flawless. The grep command didn’t catch invalid regex input, so a bad pattern would crash the tool with an uncaught “re.error.” Tests also didn’t cover exact time-window boundaries, so while these were small holes that a code review would flag in five minutes, the structure and attempt was largely correct.
Compared to Opus, MiniMax felt like a slightly less thoughtful colleague. It solves the problem, it covers most edge cases, it writes real tests, and it doesn’t over-engineer. For developers who don’t need an AI assistant to do all the thinking for them, MiniMax is probably the best Claude alternative I’ve tested. While it lags a small bit behind Opus 4.6, it’s a gap that a knowledgeable developer can close themselves. And for a fraction of the price.
The API pricing is the best part. MiniMax M2.7 comes in at roughly $0.30 per million input tokens and $1.20 per million output tokens, against Opus 4.6’s $5 and $25. That’s around seventeen to twenty-one times cheaper, depending on how your usage splits between input and output. Plus, MiniMax M2.7’s starter plan with 1500 requests every five hours comes in at just $10 a month.
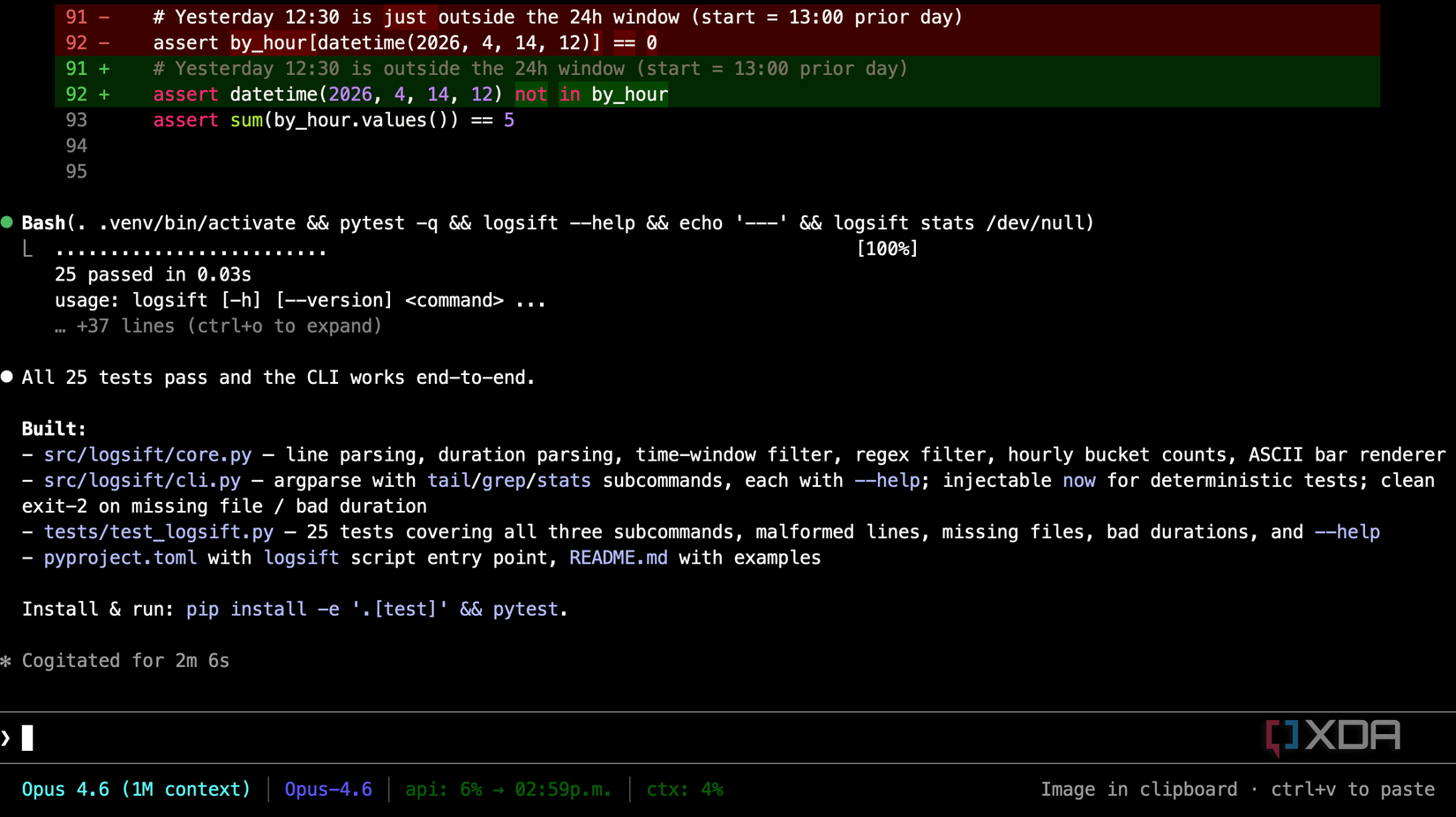
I threw Qwen3-Coder-Next into the test partly because I wanted to see how a local model stacked up, and partly because of what we lost in the next section. I ran it on my Lenovo ThinkStation PGX with Context7 wired in for library documentation lookups.
Qwen3-Coder-Next is still my go-to local coding model, and this test didn’t change that. It wasn’t perfect, the stats command bucketed hours with a quite strange “(23 – ts.hour) % 24” expression that made the chart logically wrong, and its tests were more superficial than MiniMax’s. For context, one of the tests literally just checked if the package imported. Regardless, it produced a working, installable package on a local machine, in about three minutes, without touching the cloud.
For anyone who cares about privacy, offline operation, or just not wanting their code sitting on somebody else’s server, Qwen3-Coder-Next on decent hardware is the answer. It’s not competing with Opus, but it’s powerful enough to get the job done in most instances.
The Lenovo Thinkstation PGX is a mini PC powered by Nvidia’s GB10 Grace Blackwell Superchip. It has 128 GB of VRAM for local AI workloads, and can be used for quantization, fine-tuning and all things CUDA.
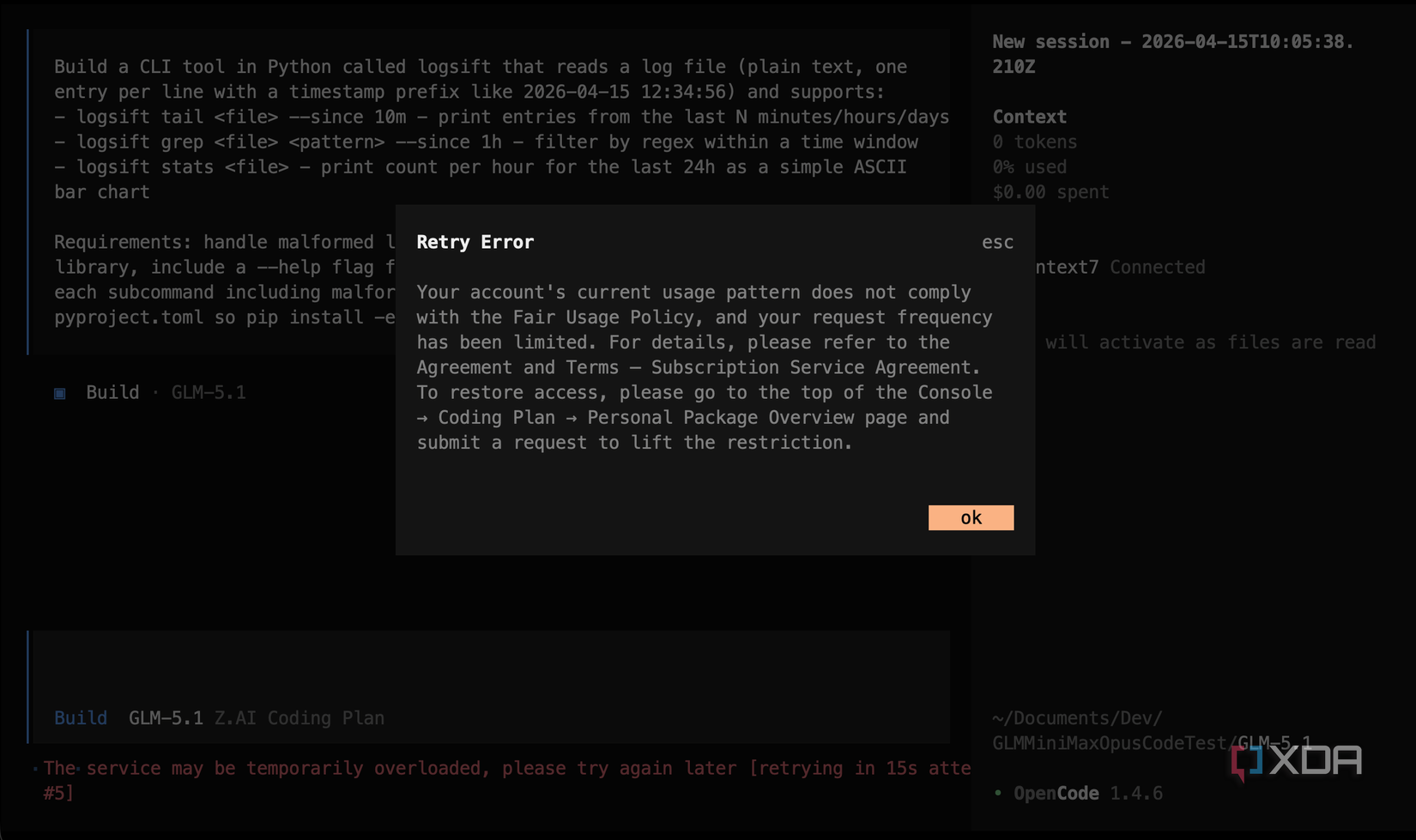
Yesterday I ran a small test on a web UI tweak for an existing project, to see how it fared with an existing codebase. It worked. Today, however, I sat down to run the logsift test. The first attempt returned a Retry Error:
“Your account’s current usage pattern does not comply with the Fair Usage Policy, and your request frequency has been limited.”
I checked my usage in the Z.ai dashboard. I was sitting on zero percent on the 5-hour quota, and just nine percent on the weekly quota. On top of that, I also was on zero percent of the monthly web search and reader quota, and my subscription was still marked as active, set to auto-renew in May. The total token count across the past seven days was around 7.4 million, almost all of it in a single spike when I’d run my first test when I got the subscription last week.
I also didn’t have the “request to lift restriction” button that the error message told me to use. It simply wasn’t there.
To make matters worse, Z.ai’s own usage policy states that “violating the Usage Rules three or more times will result in an account ban.” For the record, I hadn’t received any communication from Z.ai. I haven’t received a warning email, there’s no notification on my dashboard, and I’m left with a plan I paid for and barely even got to use.
I’m not the only one experiencing issues, either. A Reddit thread on r/ZaiGLM has multiple users in the same position, and one of them shared the boilerplate response Z.ai’s support sends when you reach out. I sent them an email, and I actually delayed writing this article when I was banned, waiting for Z.ai’s response as I assumed there must have been a mistake. Well, I received my own reply from Z.ai support, and it’s the same boilerplate, nearly word for word.
The email blames “a surge in malicious users and abusive activities” for putting “extreme pressure” on their servers, which it says has “prevented a large number of legitimate users from receiving the expected quality of service.” Z.ai’s solution to protect legitimate users from degraded service was to introduce a Fair Use Policy, but in my case, it seems to have caught a paying user who wasn’t doing any of the things the policy says it targets.
None of those describe what I did. Pi is a documented agent harness, not a raw curl script. Running one coding task on a Tuesday isn’t a flood of requests. I’m one person on my own account, and I’m not reselling anything. And that’s if I’d even received the email, which, to be clear, I didn’t. The restriction just appeared, and isn’t even reflected in my account in the way the error says that it should. And that’s without even getting into the nonsensical nature of the first reason listed.
Z.ai provides an OpenAI-compatible API endpoint and documents how to configure it in coding harnesses. That’s the entire point of the Coding plan. Every harness, whether it’s Pi, Cline, or anything else, is making HTTP requests to that endpoint. The distinction between “curl calling the endpoint” and “a harness calling the endpoint” is meaningless at the protocol level. I get what they’re trying to communicate, specifically that they’ll ban people who bypass the harness to use cheaper coding-plan pricing for raw API access, but the way it’s worded would technically cover any harness that hits that endpoint.
The response did clarify two things that weren’t in the error message, though. Firstly, bans range from “a minimum of 1 working day to a permanent ban.” Secondly, and this is the important part: “Losses of plan quotas resulting from these bans are non-refundable.” So if you get falsely flagged and lose a week of your paid plan while waiting for a review, that’s your problem.
Z.ai told me that they’re processing unban requests “in bulk” due to the high volume of inquiries, and that if my account was suspended incorrectly, they’ll lift it “immediately.” But “immediately” in the context of bulk reviews doesn’t inspire much confidence, and I’m still locked out 12 hours after receiving that email as of the time of writing.
So, that’s where I’m at currently. The policy is a three strikes and you’re out, but I haven’t received an email alerting me of any strikes, and nowhere does it actually say, apart from the API error, that my account has been restricted. From my perspective, I’ve been randomly locked out of something that I’ve paid for. Plus, the only way to get any information was to email support myself and wait for a canned response that didn’t actually address my situation. It’s not a great look.
The most frustrating part of the entire ordeal is that I went into this expecting to sing the praises of GLM-5.1. When I could actually use it, it was the model I liked most, and it’s an open-weight model, which makes it even better. The code quality was good, its tool integration felt polished, and the price-to-performance ratio was just as good as MiniMax. If Z.ai had reliable fair-use enforcement, clear warnings, and an appeal process that existed in practice rather than just in the error message, I’d be recommending it.
But I can’t recommend a service that cuts off paying customers with no warning and no accessible appeal. The $10 plan was a bargain, and honestly, it would have been at $18 as well. But it isn’t a bargain if the account just stops working before your first month is even finished. And going by the volume of people reporting the same experience on Reddit and Discord, it doesn’t look like this is just a one-off mistake, though from the outside it’s impossible to tell whether that’s bad enforcement or the policy working exactly as intended.
On top of my particular issues, the official Z.ai Discord has been inundated with users who have received similar bans, and it also opened my eyes to the fact that some users have faced even bigger problems. In one instance, two users were charged several hundred dollars for a year’s upgrade to their account, but their account’s membership was never extended. That problem happened in February, and one of those two users spent two months trying to get a refund issued. They received responses from three separate staff members over the course of two months, and the affected user was incredibly patient throughout. To give you an idea of how that chain went, here’s a quote from the second team member who entered the conversation to take over handling it:
I’m escalating directly to the people who can fix billing, not the regular support flow
Unfortunately, the affected user has told me they still have not received their money back.
For day-to-day work, Claude Opus is still the best model I’d recommend overall, given its speed, complexity, and ease of use. If Claude’s usage limits keep shifting in a direction I don’t like, MiniMax M2.7 is the alternative I’d pick without hesitation. It’s close enough to Opus for most real work, the pricing is brutally cheaper, and nothing about my experience setting it up or using it made me nervous.
For anything local, Qwen3-Coder-Next on a machine with enough VRAM is still remarkable, and I keep coming back to it for privacy-sensitive tasks like reverse engineering and analysis.
GLM-5.1, though, I unfortunately can’t recommend at all right now. It’s a genuine shame given how much I liked it when it worked, but until Z.ai fixes its fair-use enforcement, sends warnings before bans, and makes the appeal process actually accessible, the risk isn’t worth the money you save. And in my case, the money I did save vanished the moment the account got locked. I’ve already seen users with much longer subscriptions on higher tiers than mine facing similar bans, so while I’m down $10, there are users who are questioning the several hundred dollars they invested in a subscription.
If you’re shopping for a Claude alternative because of the limits, MiniMax M2.7 is the one to try. Just maybe don’t put all your eggs in any single basket right now. The whole reason I ran this test in the first place is that Claude’s limits seemingly keep moving, but that lesson cuts both ways.