
The topic Apple researchers built an AI that tests several ideas in parallel before answering is currently the subject of lively discussion — readers and analysts are keeping a close eye on developments.
This is taking place in a dynamic environment: companies’ decisions and competitors’ reactions can quickly change the picture.
In a new paper, a team of Apple researchers details a creative framework that improves LLM answers in math reasoning, code generation, and more. Here are the details.
In a newly-revised study titled LaDiR: Latent Diffusion Enhances LLMs for Text Reasoning, Apple researchers, alongside researchers from the University of California, San Diego, detail an interesting way to improve the quality of answers generated by large language models (LLMs) in certain domains.
In the past, we’ve discussed diffusion models, which generate text by iterating over many tokens in parallel with each pass, in contrast to autoregressive models, which work by calculating and predicting tokens one by one.
Apple has even looked at diffusion models applied to protein folding prediction and coding, which is endlessly interesting.
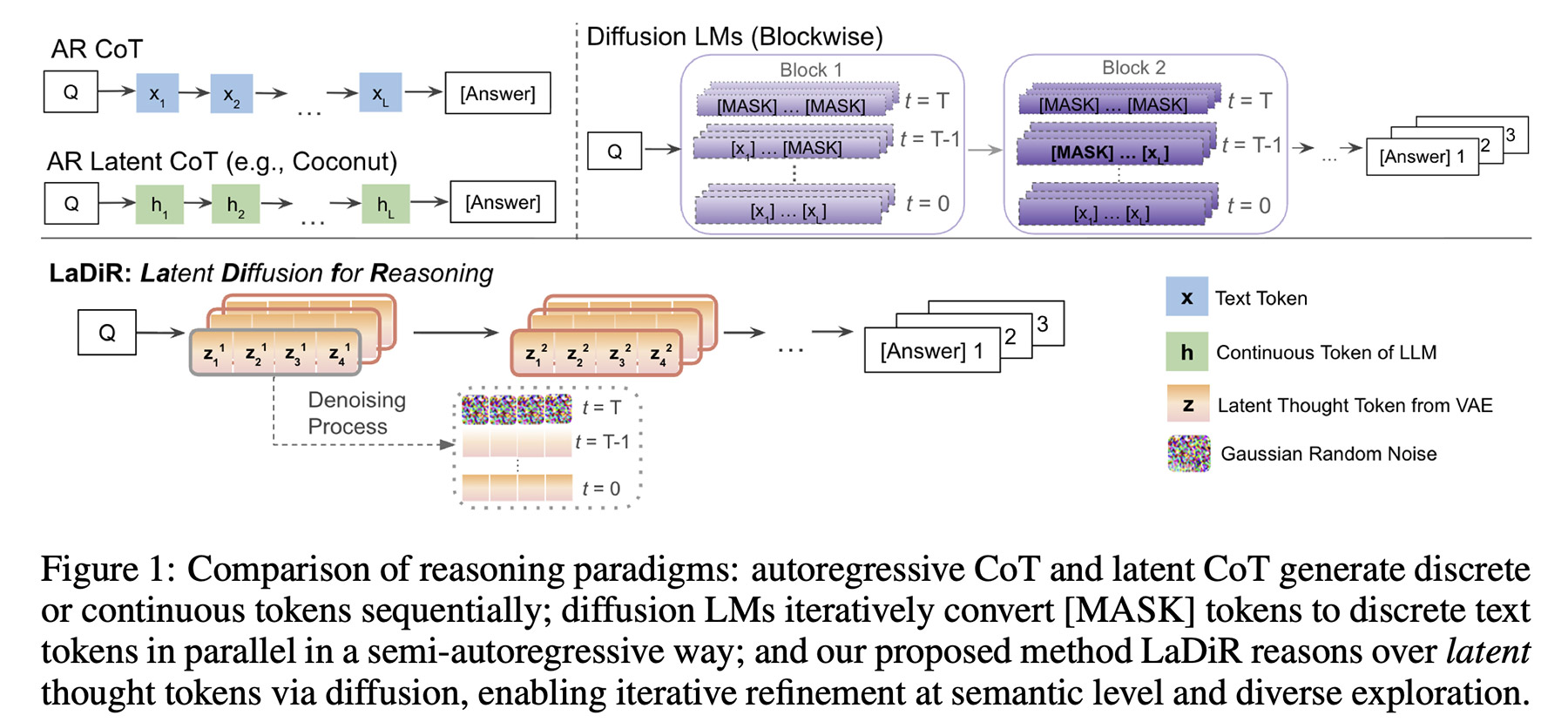
What LaDiR does, in a nutshell, is combine both approaches: it adopts diffusion during the reasoning process, and then generates the final output autoregressively.
More than that, it actually works with many reasoning paths in parallel, each one running its own diffusion process, with a mechanism that pushes them to explore different possibilities, thus producing a diverse set of candidate answers.
They explain that during inference time, when the model is essentially coming up with what and how it will answer to the user’s prompt, LaDiR generates a series of hidden reasoning blocks, each starting as a random pattern (or, noise) and gradually being refined into a more coherent step.
Once the model determines it has done enough reasoning, it switches to generating the final answer autoregressively, one token at a time.
The key detail is that LaDiR can run several of these reasoning paths in parallel, with a mechanism that encourages it to explore different possibilities to avoid them all converging on the same idea too early, defeating the purpose of the whole thing.
importantly, LaDiR isn’t a new model per se, but rather a framework that builds on top of existing language models. It changes how they reason through a problem, rather than replacing them entirely.
In the study, the researchers applied LaDiR to Meta’s LLaMA 3.1 8B for math reasoning and puzzle planning, and Qwen3-8B-Base for code generation.
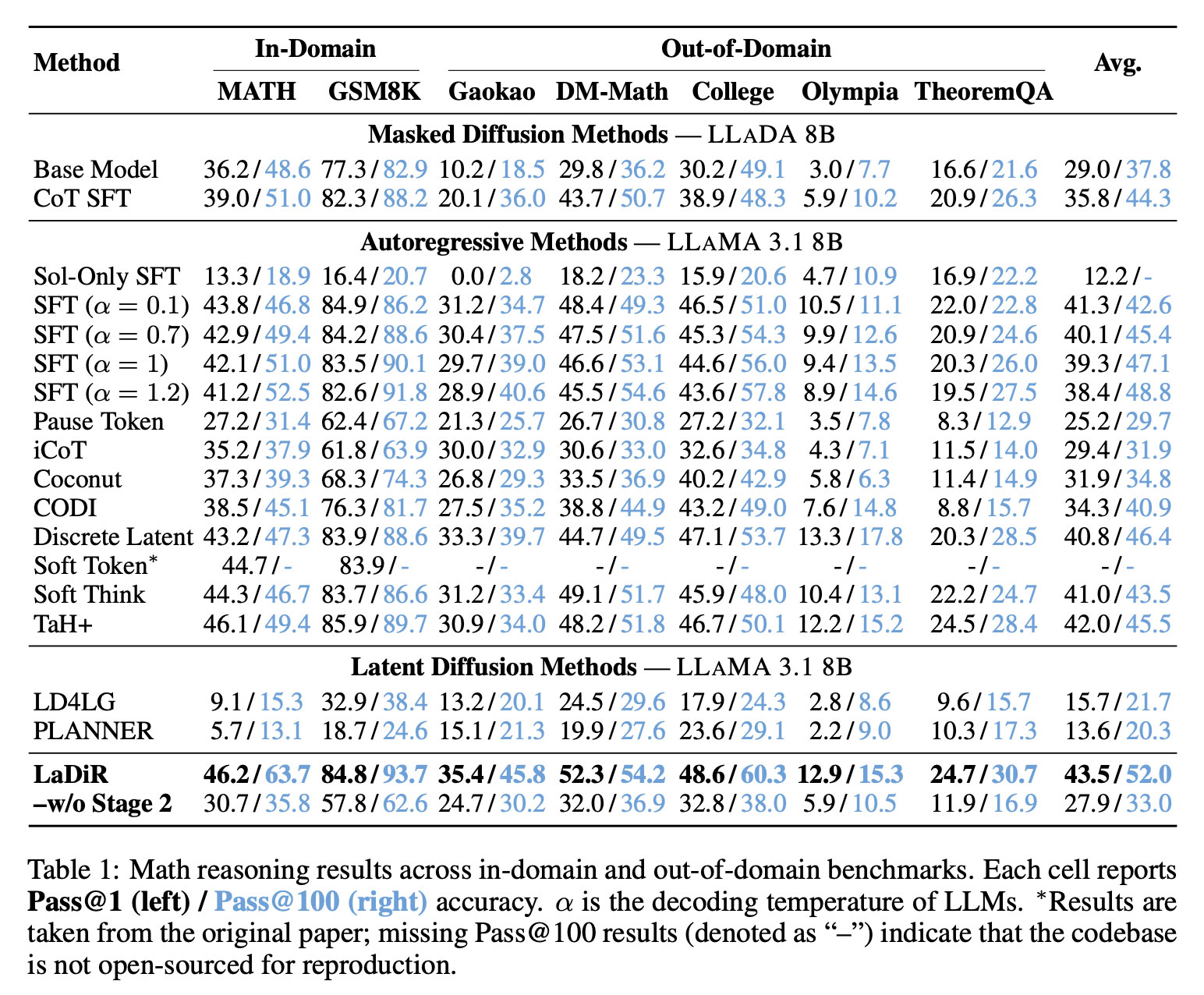
On math benchmarks, LaDiR achieved higher accuracy than existing approaches and demonstrated stronger performance even on more difficult, out-of-distribution tasks.
On code generation benchmarks such as HumanEval, LaDiR produced more reliable outputs, outperforming standard fine-tuning by a noticeable margin, particularly on harder problems.
And in puzzle-style planning tasks, such as the Countdown game, LaDiR explored a wider range of valid answers than any baseline model, and found correct solutions more reliably than all general-purpose baselines. It did, however, fall short of a specialized, task-specific model on single-attempt accuracy.
While some of the aspects of the LaDiR paper can get quite technical, it is a worthwhile read if you’re interested in the inner workings of large language models, and novel approaches to improve performance on text generation.