The topic Running local LLMs every day for five months broke every assumption I had about them is currently the subject of lively discussion — readers and analysts are keeping a close eye on developments.
This is taking place in a dynamic environment: companies’ decisions and competitors’ reactions can quickly change the picture.
I got into local LLMs because it seemed interesting, if I’m being completely honest. Running my own AI on my own hardware just felt like something worth trying, and not because I had a specific gap to fill or super strong feelings about data privacy at the time. The novelty was the whole draw at first.
The privacy angle came a bit later and more gradually as I learned more about data privacy. There are documents I’d rather not hand to Google, OpenAI, or Anthropic’s servers now, and once the local AI setup was working, reaching for it in those cases made obvious sense. But that never turned it into a full replacement for cloud AI – I still have Claude open most of the day, for example. This isn’t a “local LLMs beat everything” argument because that’s not my experience. It’s more that after about four to five months of running both, I have a clearer sense of what I was wrong about going in, and what ended up mattering more than I expected.
The number I looked at first was parameters – 7B, 12B, 20B, etc. – because that’s the number everyone talks about. Bigger means better, roughly. And it’s why I went with a 20B general-purpose model at first (gpt-oss), which I managed to run thanks to GPU offloading. A bigger parameter count being better is not completely wrong, but it ended up being the least useful thing I paid attention to. What actually bit me was context window, which I’d basically ignored because I didn’t fully understand what it meant in practice at the time.
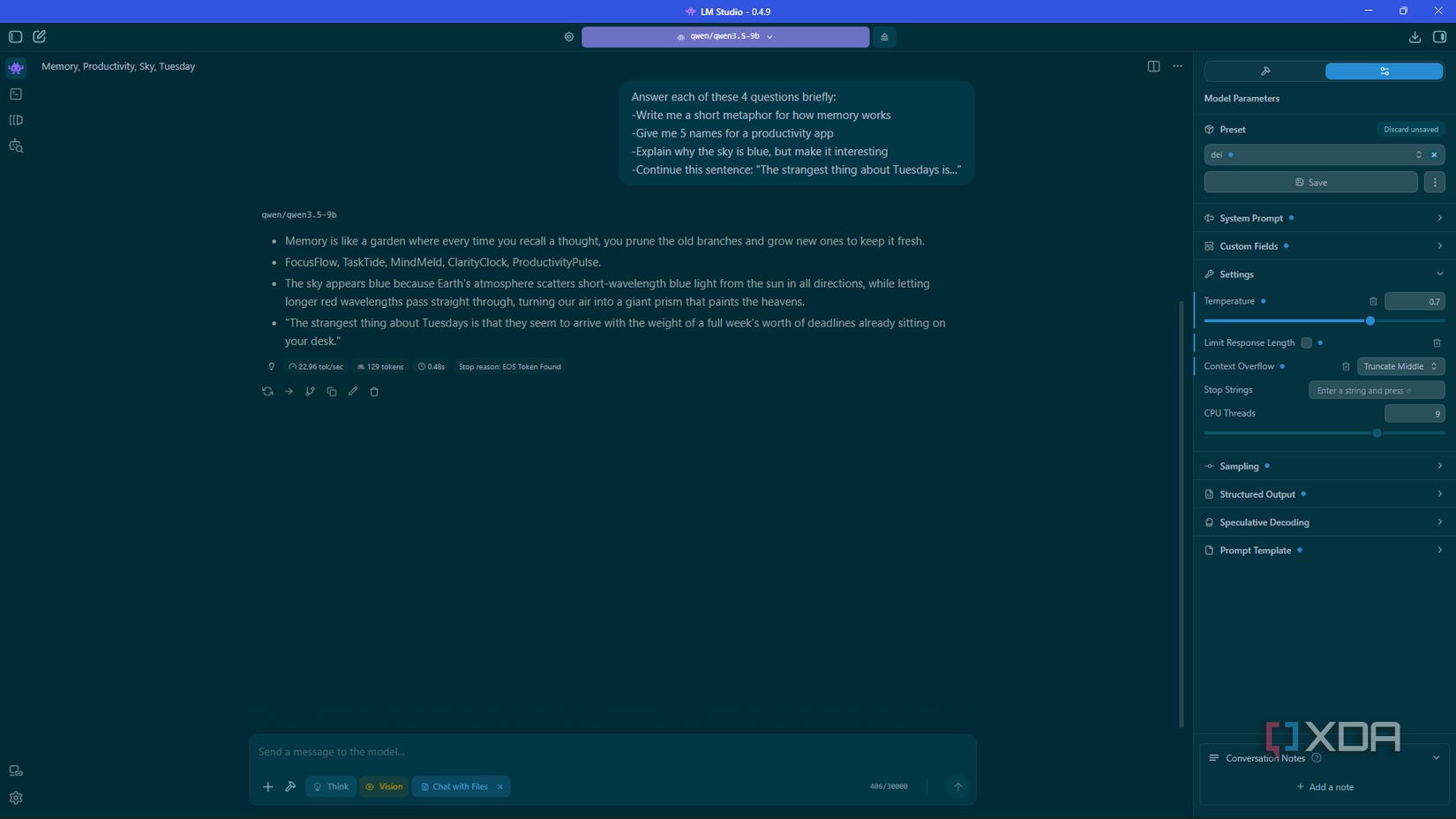
I’m running an RTX 3070 with 8GB VRAM, and ended up swapping my 20B model for a 9B (qwen 3.5) and got noticeably better results. The reason is because of its architecture – it’s lighter on VRAM because of Gated DeltaNet, whereas standard transformers keep climbing. So I can push to 60k tokens on 8GB without it struggling, which means longer sessions where the model actually remembers what we were doing an hour ago. The parameter count tells you something about what a model is capable of in theory. Architecture is what determines how much of that you can actually reach on the hardware you have.
This one crept up on me, but I’m not complaining. While Cloud AI is still more powerful, it has its own limits – aka rate limits, message caps, API hiccups, server shutdowns, unwarranted censorship, stuff like that. With a local model, none of that is a variable. It’s there when my internet isn’t, it’s also there at 2am when I’ve apparently burned through my Claude quota even on the paid plan, and because there’s no sense of burning through anything, I can use it more freely. This was definitely a nice surprise about using local AI (though in hindsight, I’m not sure why I expected anything less).
When I first opened LM Studio I treated it like another chat window and ignored basically everything else. My system prompt was empty, temperature sitting at the default, and I was prompting it like a search engine. The responses felt weak and I assumed that was just the ceiling on local models. But, temperature down to 0.7, presence penalty nudged up, a system prompt that tells it who I am and what I want, and prompting iteratively instead of expecting a single answer to land, gave me much better results. That’s before even touching context length, which is its own thing. The setup you load a model into shapes what it can do more than most people expect.
A lot of content I see goes straight to “get a better model.” Usually the actual problem is sitting in the settings panel of your runner.
There’s a phase early on where every model that comes up in a Reddit thread or gets mentioned in a YouTube video goes into the queue, you run the same prompt through all of them, and somehow this becomes its own hobby that has nothing to do with actually using a local LLM. The comparisons are interesting if you’re coming at this from a developer or benchmark angle – there are real differences worth caring about there. But if your reasons for running local are closer to mine, privacy and just liking that it exists, the gap between decent models is much smaller than the time you’ll spend chasing it.
Once I landed on Qwen 3.5 I mostly stopped looking. There are probably still other options worth exploring (I’m actually in the process of giving Gemma 4 a spin just to see what the hype is about). But the benchmark loop is often just a different hobby from actually using a local LLM.
The framing that local LLM content loves is “replace your cloud AI,” and I get why it’s appealing as a pitch – I’ve definitely framed it that way myself. However, realistically, cloud AI isn’t going anywhere for me. I couldn’t do my daily tasks without Claude or study materials without Gemini at this point – they’re extremely capable and their products have dedicated features for things like research, folder organization, study materials, automated tasks, and much more. There’s also a level of polish that I can’t get locally.
But local AI is still my go-to for anything I’d rather keep on my machine. I don’t have to worry about my personal health or financial data being retained on Google’s or Anthropic’s servers for the next however many years. And it’s a nice-to-have, not going to lie – I like the concept of having a chatbot on my terms and owning all the conversations.
The novelty was what got my foot in the door, and the privacy is what kept me staying. That’s probably the most honest endorsement I can give local LLMs. It didn’t fully replace anything or blow my expectations out the water, and it took more setup than I anticipated. But, now I have a tool that’s always available, not restricted, and lets me keep my data to myself, which is pretty cool to me.