The topic I stopped running the biggest local LLM that could fit, and a 2B model handles 90%… is currently the subject of lively discussion — readers and analysts are keeping a close eye on developments.
This is taking place in a dynamic environment: companies’ decisions and competitors’ reactions can quickly change the picture.
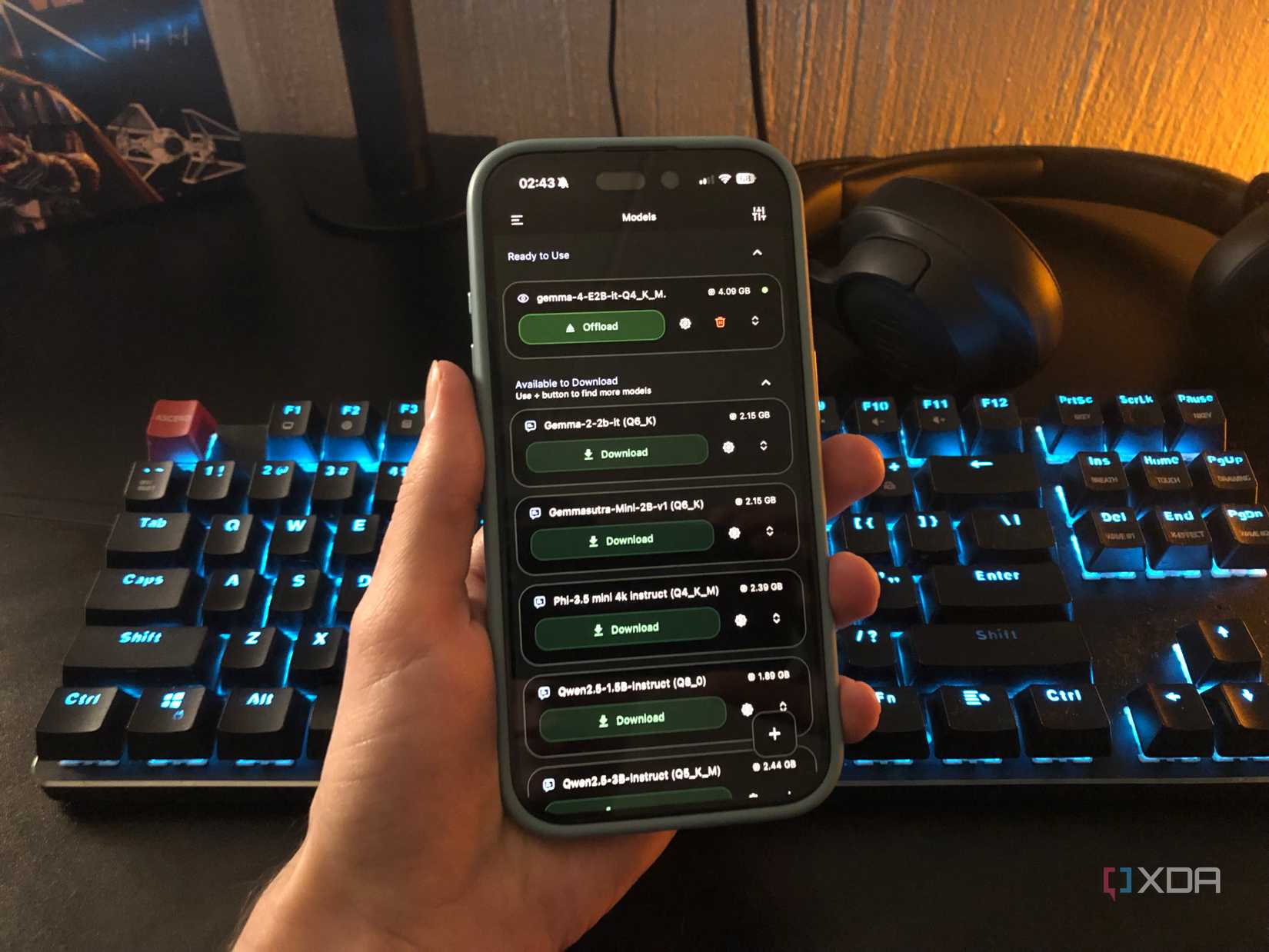
If you’ve got a regular consumer GPU and have been curious about running a local LLM, there’s a good chance you’ve either assumed it wouldn’t work or tried and had a rough time. Most of the bigger open-weight models won’t fit, and the ones that do tend to run so heavily quantized that the experience isn’t very smooth. Then models like Qwen 3.5 9B started landing, and the bar for “usable local AI on modest hardware” actually lowered a bit. I’ve been running it on 8GB VRAM for months now.
But even the 9Bs come with caveats. You’re often using everything your GPU has, so anything else running at the same time gets squeezed, and the context window stays small unless you make trade-offs elsewhere. That was kind of my situation. And then I noticed something: the smaller models, the ones built specifically for limited hardware, were actually doing the job better.
The “B” in any model name is just the parameter count – billions of knobs the model adjusts during training. More knobs technically mean more capacity for nuance, but only if you’re actually asking the model to do something nuanced. Most of what I use local AI for is explaining concepts, summarizing things, talking through a screenshot, general back-and-forth – I treat it like a chatbot more than an assistant. And the thing is, you reach that goal way before you need 9B parameters.
Where the bigger models genuinely pull ahead is dense coding, multistep agentic workflows, long-form structured output, and things along those lines. So if you’re not doing those, you’re basically paying for capability you’re not using. By paying I mean figuratively: it shows up as slower tokens per second, heavier disk footprint, and quantization compromises that often make a bigger model perform worse than a smaller one running at full quality. So if your hardware is modest like mine, sometimes a 9B at Q3 is genuinely worse than a 2B at Q8.
Gemma 4 E2B is part of Google’s Gemma 4 family that dropped at the end of March 2026. Per-Layer Embeddings (PLE) let each decoder layer hold its own small embedding for every token, used as a lookup rather than full compute. So the effective parameter count stays low even though the model carries more underneath. It’s natively multimodal with vision, text, and audio input. 128K context window, 140+ languages, tool calling, and configurable thinking modes. Google explicitly positions E2B and E4B for edge, meaning phones, laptops, Android, the AI Edge Gallery.
Qwen 3.5 2B came out a few weeks earlier in March 2026 from Alibaba’s Qwen team, as part of the small series alongside the 0.8B, 4B, and 9B. It’s a dense 2B vision-language model that uses Gated DeltaNet hybrid architecture, which is the same trick the 9B uses to keep KV cache small at long contexts. The wild part is the 262K native context window, extensible to over 1M tokens. On a 2B. It supports both thinking and non-thinking modes (non-thinking by default for the small variants) and Alibaba calls out tool calling as one of its strengths.
Gemma 4 E2B is my go-to local chatbot on mobile, and weirdly also on my Chromebook (a bit slow but it runs). The personality is the part I like about it; it’s conversational and expansive, and explains like a cloud chatbot would (it even drops in emojis without being told to). The vision is the bigger sell for me though. I send it screenshots constantly when I’m setting up a new app or learning something visually, and it actually reads what’s in there, ranging from UI elements and design references to charts and handwritten notes. That alone makes it worth keeping on my phone.
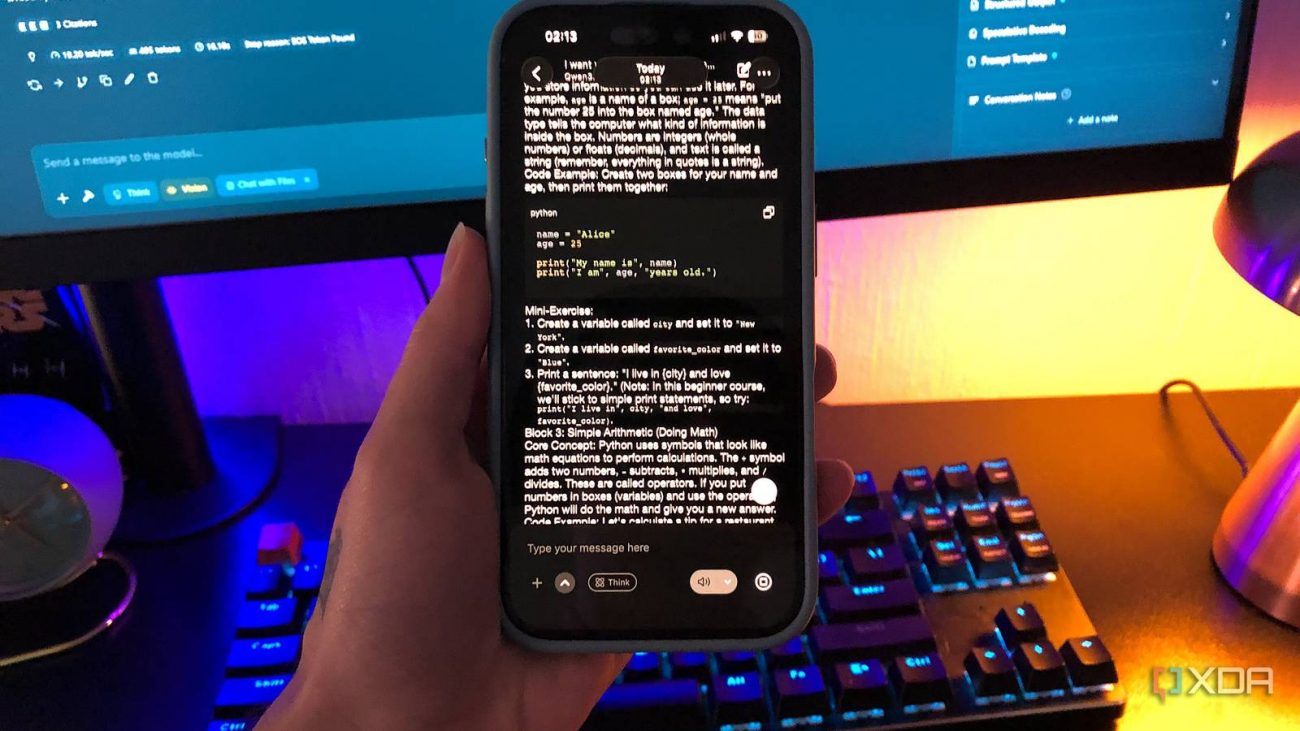
Qwen 3.5 2B is newer to my rotation and feels different. Less warm, more grounded, more focused-assistant than friendly-chatbot. It’s a keeper when it comes to structured tasks like text classification and breaking down dense information – I also got it to create a weekend Python 101 course for me. Vision works here too, but I still prefer Gemma for working with images.
Compared to their bigger siblings, the 2Bs do lose ground on the harder stuff. When it comes to multi-step reasoning and long-form structured output, Qwen 3.5 9B and Gemma 4 E4B do pull ahead. Gemma 4 12B should as well, but it actually stretches my hardware a little more, which means I can’t really run much else when using it. Tokens per second is the other gap – the bigger models on PC do generate faster than the 2Bs running on my phone, but that’s not a fair comparison and it doesn’t matter much in chat anyway.
A 2B model isn’t a stripped-down version of a 9B. Gemma 4 E2B and Qwen 3.5 2B were architected for edge devices from the start, with efficiency choices as part of their architecture and how they handle attentions and parameter loading. So calling them “lite” versions kind of misses what they are. They’re purpose-built for hardware that’s not trying to run a workstation model. I still keep the bigger ones around for heavier workloads, though.