
The topic My local LLM was just a chat box until Hermes Agent let it run scripts, files, and… is currently the subject of lively discussion — readers and analysts are keeping a close eye on developments.
This is taking place in a dynamic environment: companies’ decisions and competitors’ reactions can quickly change the picture.
I’ve been using Hermes Agent for a while now, and the more time I spend with it, the less I think about it as another chat interface. The model matters, obviously, but a chat box is a mere conduit once the model can read files, run scripts, send messages, schedule work, and talk to the services I already use.
My setup right now is Qwen3.6 35B-A3B running locally on a Lenovo ThinkStation PGX. Hermes sits around it as the agent layer, which means the model can pull from APIs, parse a zip file of emails, create files, send me reports over Discord or Telegram, and run a job while I’m not sitting there watching it.
A local LLM by itself is fine for asking questions, but it doesn’t become genuinely useful until it can act on the answer, and model size only gets me so far here. Qwen3.6 35B-A3B is doing the reasoning, but Hermes is the part that allows the model to call a script, read a directory, save an API key in a local env file, or send the output back to me later.
These are just some of the ways I use my local LLM in Hermes Agent to be more organized and productive, and while a lot of them are external services, the reasoning layer, scripts, files, and automation all run on my own machine. And nothing leaves my network unless I specifically want it to.
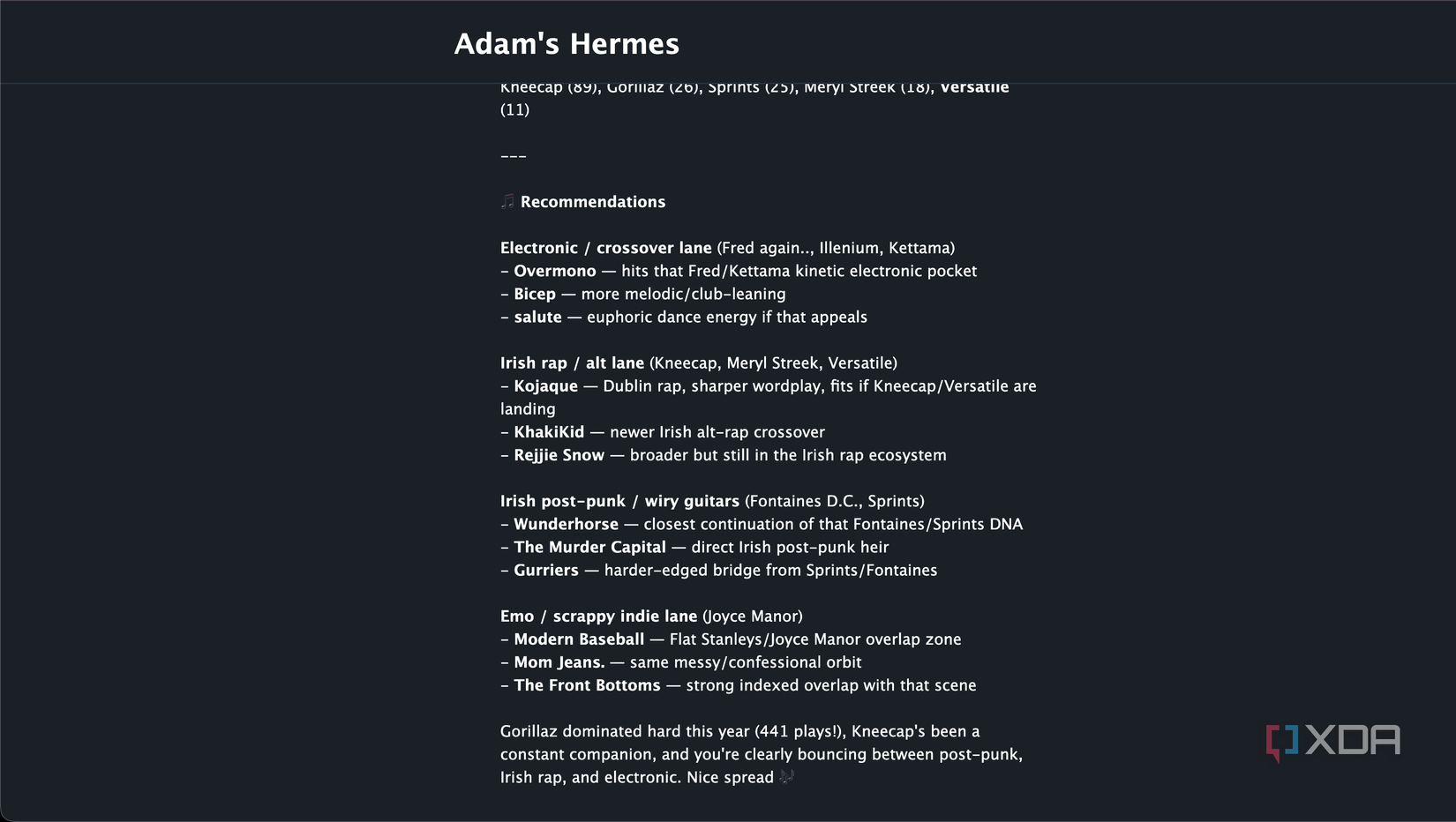
One of my favorite workflows that I use with Hermes pulls my Last.fm history and turns it into a music report. It uses a Last.fm API key, fetches my top artists, tracks, albums, and recent scrobbles, then has the local model interpret the results instead of guessing from whatever artist I happen to mention in a prompt.
The 12-month pull gave it a much better picture of what I actually listen to. Gorillaz, Kneecap, Sprints, Fred again, Illenium, Meryl Streek, Joyce Manor, Halsey, Kettama, and Black Country, New Road are just some of the artists that it picks up, and it can also lean into more recent snapshots of listening, too. An interesting anomaly that it dealt with was an Irish rap group called Versatile.
Versatile turned out to be a problem artist for Last.fm, and one I was surprised my local LLM actually dealt with correctly. You see, Versatile is the name of a French black metal band, and Last.fm appears to allow for duplicate names through a unique MusicBrainz Identifier, or MBID. Both Versatiles have two separate ones, but Last.fm’s function that allows you to programmatically find similar artists will resolve it to the wrong Versatile unless explicitly given the MBID. My Hermes instance recognized that, and baked a correction into the workflow in case it came up again.
The workflow is also set up as a skill that I can call at any time instead of being a one-off prompt. The API key is stored in a local env file with restrictive permissions, not in Hermes memory. There are scripts for the yearly stats pull, the readable report, and my account wrapper, plus a weekly script-only cron job that sends the week’s report to my ongoing chat on a Monday morning.
If I’m looking for new music, I don’t want to paste my listening history into a chatbot every week. I want the machine to pull the data, interpret it, remember the weird edge cases, and only bother me with the useful output.
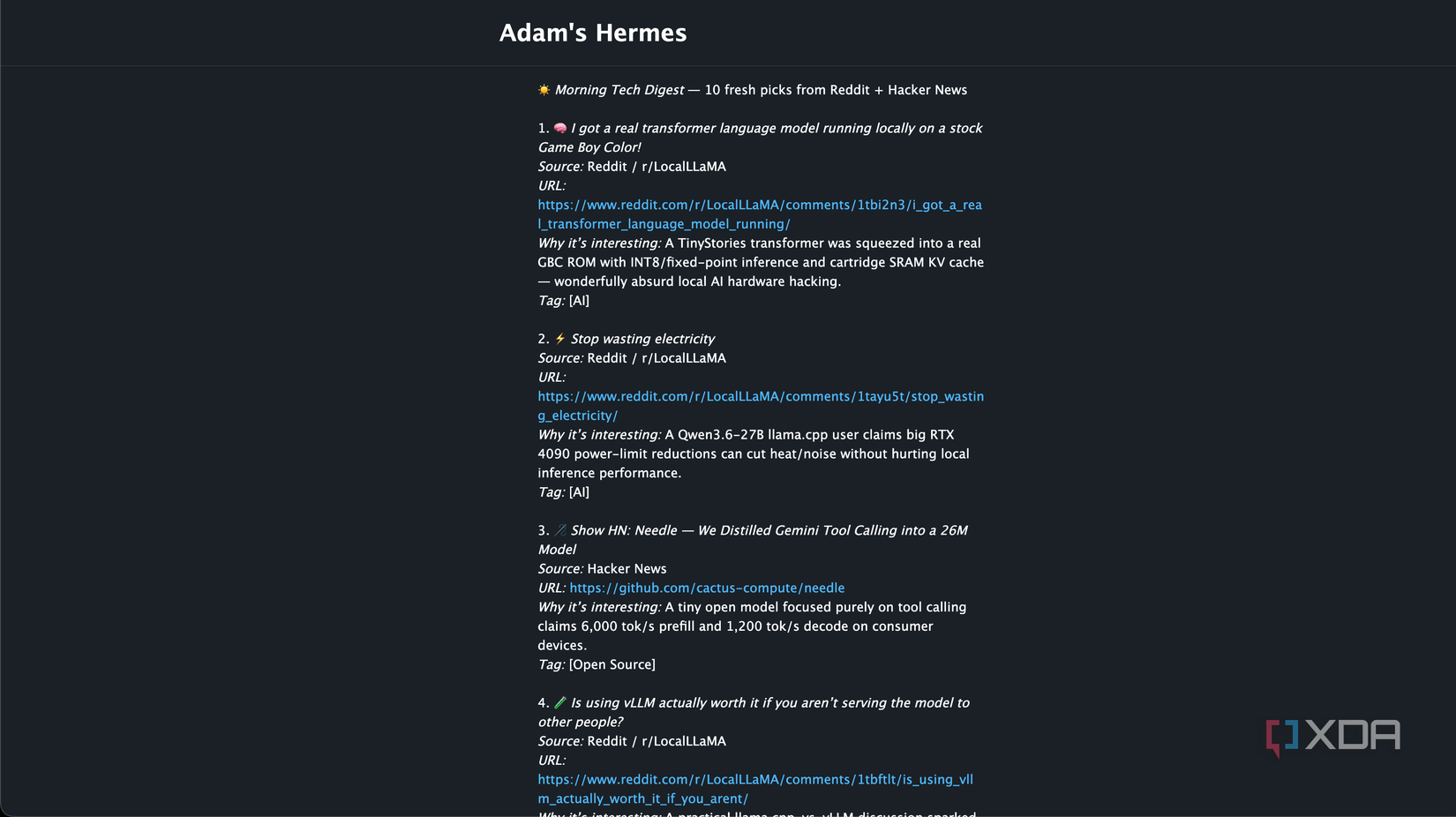
I also have Hermes send me a daily reading queue every morning. The cron job pulls Reddit trends from places like r/esp32, r/homeassistant, r/selfhosted, r/homelab, r/sysadmin, and r/LocalLLaMA, as well as the top Hacker News stories. It turns the places I already check into a smaller daily digest that I can read through with ease.
A Python script does the collection work first, then the agent turns that raw data into a handful of headlines, a brief summary, and a source thread or story attached. It runs at 8 AM server time and delivers the result back to me, so I start the day with a tailored feed of news to check out and read through.
The local model still helps once the raw items are gathered. It can decide which stories are worth reading and are more tailored to me, group related posts, and ignore threads that are ultimately boring. For Home Assistant, ESP32, and LocalLLaMA, the best posts can often be buried or easily missed.
It’s a small workflow, but it’s one I actually want running in the background. A local model doesn’t need to be constantly interactive to be useful. Sometimes the best use is waking up to a short list of things to read that already has the junk filtered out.
The most practical example I used this for so far was Computex. I had a messy pile of event-related emails, meetings, and things I wanted to do, and an event like that can be incredibly overwhelming with the sheer volume of communication hitting my inbox. I had an idea, though: what if I downloaded my emails, gave them to my local LLM, and had it pick out the dates, times, and event locations? It was originally just a test, because truth be told, I didn’t really think it would work.
I gave Hermes a zip file, and my local LLM unpacked the email data, parsed the messages, checked my existing Computex trip plan, and built an organizer from it. It didn’t just give me a vague summary. It pulled out who would be worth following up with, what the reply would be for, how urgent each one was, and highlighted interesting things at the event for me. I thought it was interesting how comprehensive it was, as it also highlighted which emails didn’t need to be followed up with. That last part is underrated, because knowing what not to chase is part of staying organized too.
When I asked for time slots, it grouped them by company and separated confirmed events from options I still needed to pick. It pulled out meeting windows, briefings, tours, receptions, and wait-and-see threads without forcing me to read every email again. Because I had thought it wouldn’t work, I went through and verified every single one. I was shocked to discover that it was completely accurate. Every event, every date, every location, was plucked out and served back to me perfectly.
After I realized that it was completely accurate, I wondered what I could try next. I asked it to make an ICS file that could import to Google Calendar, and that’s exactly what it did. A model spotting dates in emails is one thing, but a local agent turning a zip file of event threads into a planner, a reply queue, and calendar data I can import is much closer to what I want from personal automation.
There are obvious limits here. Time zones, vague meeting offers, duplicate threads, and tentative invites can all trip up a calendar workflow, so I would still verify every aspect going forward. However, verification is much easier than building the whole plan manually from a pile of emails.
In terms of privacy, I didn’t mind that either, because everything runs locally. My emails don’t have to go to the cloud for this workflow to be possible, and I don’t have to give the LLM access to my emails directly. I just downloaded what I needed, zipped the file, and dumped it in the chat. Hermes did the rest.
Using Hermes through Telegram is as interesting as it sounds. I can ask it to check something, run something, summarize something, or create something, and the result comes back in the same chat. A normal local chat UI doesn’t do that unless I’m sitting in front of it. I have the ability to message it from my phone, my laptop, or my PC, and all of them give the exact same quality of response.
It also makes all the other workflows easier to use. The Last.fm report comes back to the chat. The reading queue comes back to the chat. A calendar file or summary can be generated from something I send over. I don’t need to use SSH or open a browser UI every time I want the model to do something small.
There are still permissions and safety boundaries to think about. A messaging gateway is an attack surface, and I don’t want an agent with file and terminal access to be casually exposed to everyone. That’s why it all runs in a firewalled LXC and I do things like manually drop my emails in the chat, rather than giving it unfettered access to my email. However, with the right limits, it turns a local LLM from something useful from anywhere at any time.
Voice messages are a small quality-of-life feature, but they change how often I’m willing to use the system. If I’m on my phone, typing out a long instruction is annoying enough that I often won’t bother. But sending a voice message is a lot easier, especially when the task is a half-formed instruction, a reminder to process something later, or a longer explanation that would be annoying to type on a phone keyboard.
Hermes’ local speech-to-text path uses faster-whisper, with model options like tiny, base, small, medium, and large-v3. That means the transcription part can run locally too, assuming you’ve configured it that way. There are cloud options as well, like Groq, OpenAI, and Mistral, but for this kind of workflow the local path is the one that makes the most sense to me. It’s really fast as well, and a two minute voice message I sent the other day to create a basic note to come back to was transcribed in about thirty seconds.
The voice message doesn’t need to be perfect prose. I can ramble and even with failed transcriptions, it often still understands the point of what I’m saying, There was one where I wanted it to add another model to my config, and it understood “Qwen” as “Quenn”, but my local model still figured out that I probably meant Qwen and continued as normal.
Unfortunately, it’s not magic, and Whisper can still mistranscribe things in a way that breaks the model’s understanding of your prompt. That includes names and acronyms, but it gets it mostly right. For asking my local model to do something while I’m away from the keyboard, it removes just enough friction that I use it more. I wouldn’t use it if for sending messages or changing anything in a file (and I will admit, seeing “Quenn” as a transcribed message had me worried), but it’s a really nice, convenient feature to have.
Rather than giving an agent access to my email, I recently discovered and set up AgentMail. It gives my local LLM its own email identity that I can send emails to if I want it to read something. Your LLM can also send, receive, and act on emails through an API, though I still only scoped the API key to read only access. I don’t want my LLM sending out emails to the outside world as that opens up too many risks, but giving it read-only access is perfect.
It’s kind of similar to the Computex workflow, except I still wouldn’t forward anything sensitive to it. Still, email is where a lot of real-world logistics still happen, and there are plenty of things that you could still forward to a dedicated inbox for an agent and have it be actioned.
A local LLM is easy to demo and hard to keep using if all it does is sit in a chat window. Hermes changes that because it makes the model part of a system I can actually build around: scripts, APIs, cron jobs, files, voice messages, and chat delivery. I’ve found mine incredibly useful, both because of the ways I can use it and how convenient it is to use it.
All of this is why Hermes has stuck around on my machine and become something that I actually use frequently. I’m not going to go connecting it to all of my services, and for the most part, it’s gated by what I explicitly send it. It doesn’t just let me talk to a local model. It lets the local model do work.