The topic I use Claude Pro, Qwen 3-Coder, and Gemma 4 together, and it’s the most… is currently the subject of lively discussion — readers and analysts are keeping a close eye on developments.
This is taking place in a dynamic environment: companies’ decisions and competitors’ reactions can quickly change the picture.
AI has found its way into almost every workflow imaginable. Large language and image models have become nearly inseparable from creative, programming, and research-based work, and for many professionals, the productivity enhancement is so compelling that they’re no longer optional to use. It’s also true that the best flagship models from Google, OpenAI, and Anthropic are among the most expensive to run, and using them on a daily basis to drive productivity quickly becomes an exercise in resource management.
That said, there are some very capable open-source models available today at no cost, and while some users have managed to replace their paid subscriptions entirely, I’ve found that going fully open-source comes with a sour set of compromises. The sweet spot, in my experience, lies in a hybrid approach. Here’s how I’m pairing a premium model with two open-source ones, and why the combination works better than using either alone.
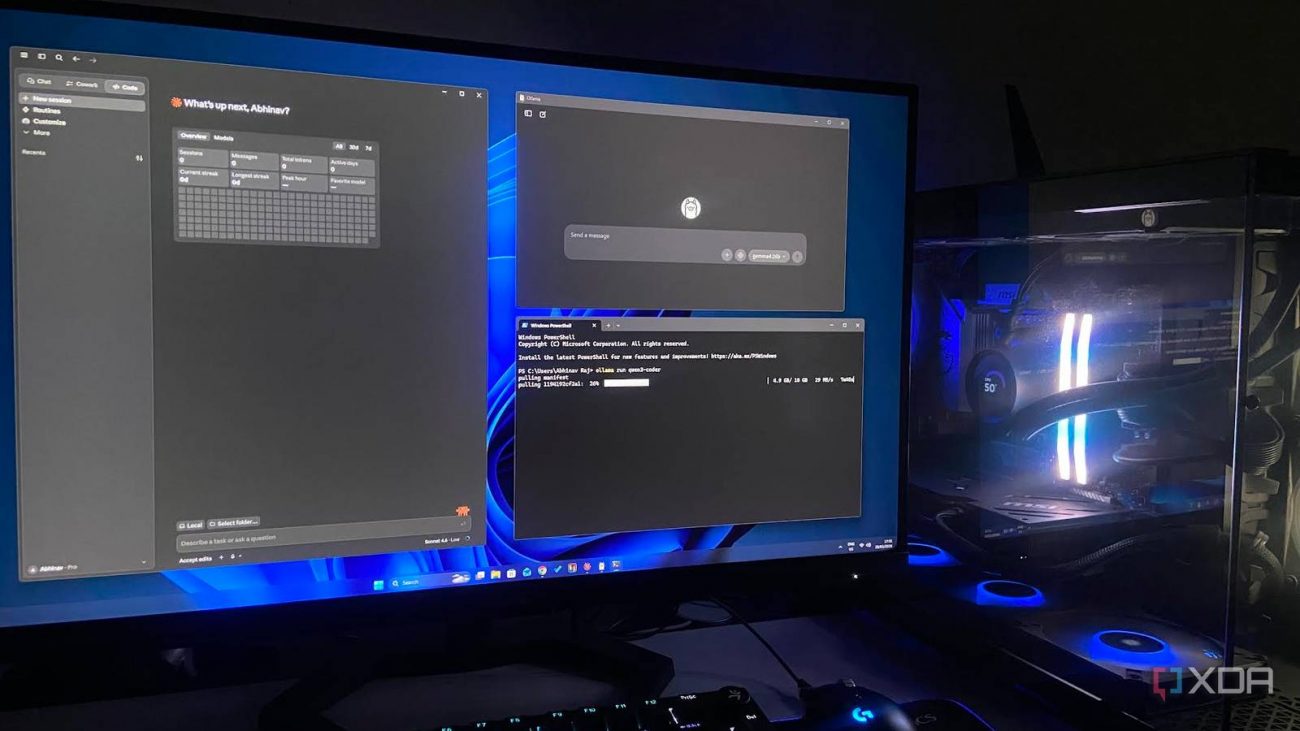
If you’ve read my earlier commentary on hybrid LLM workflows, you’ll know that I’ve been a vocal advocate for pairing a premium model with a locally hosted one. What I’ve since discovered, is the fact that two models weren’t quite enough. The missing piece, at least for my workflow, was a dedicated coding model, and that’s where Qwen 3-Coder 30B enters the picture.
The “division of labor” is quite simple to understand, especially since it’s built around each model’s individual strengths. Claude Pro, naturally, remains the premium anchor, which is reserved for the tasks that demand frontier-level reasoning and the platform-exclusive features (such as interactive visuals and artifacts) that I rely on. Qwen 3-Coder takes over the coding lane, handling the iterative code-generation cycles, boilerplate, and the back-and-forth debugging that would otherwise eat through my Claude allowance.
Gemma 4 24B is tasked with other generative tasks, such as first drafts, summarization, brainstorming, and everything that comes in between. At this point, you might wonder why I’m not using ChatGPT for this. The answer really is quite simple, and it is the fact that Gemma 4 runs on the same local Ollama interface as Qwen 3-Coder, which means both open-source models operate under one unified workflow. Amongst the three, there’s almost no redundancy, which means every model is operating in the lane it is best suited for.
The best way to illustrate how this workflow operates is to walk through what a typical session looks like. If I’m building a Python utility from the ground up, the first place to start is Gemma 4, where I will outline what the utility should do, manage baseline expectations, brainstorm the structure, and have it evaluate the constraints and opportunities surrounding the idea. Gemma 4 24B is fast, responsive, and lighter than the 31B model, which makes it perfectly capable of producing a working first draft that I can evaluate and build on.
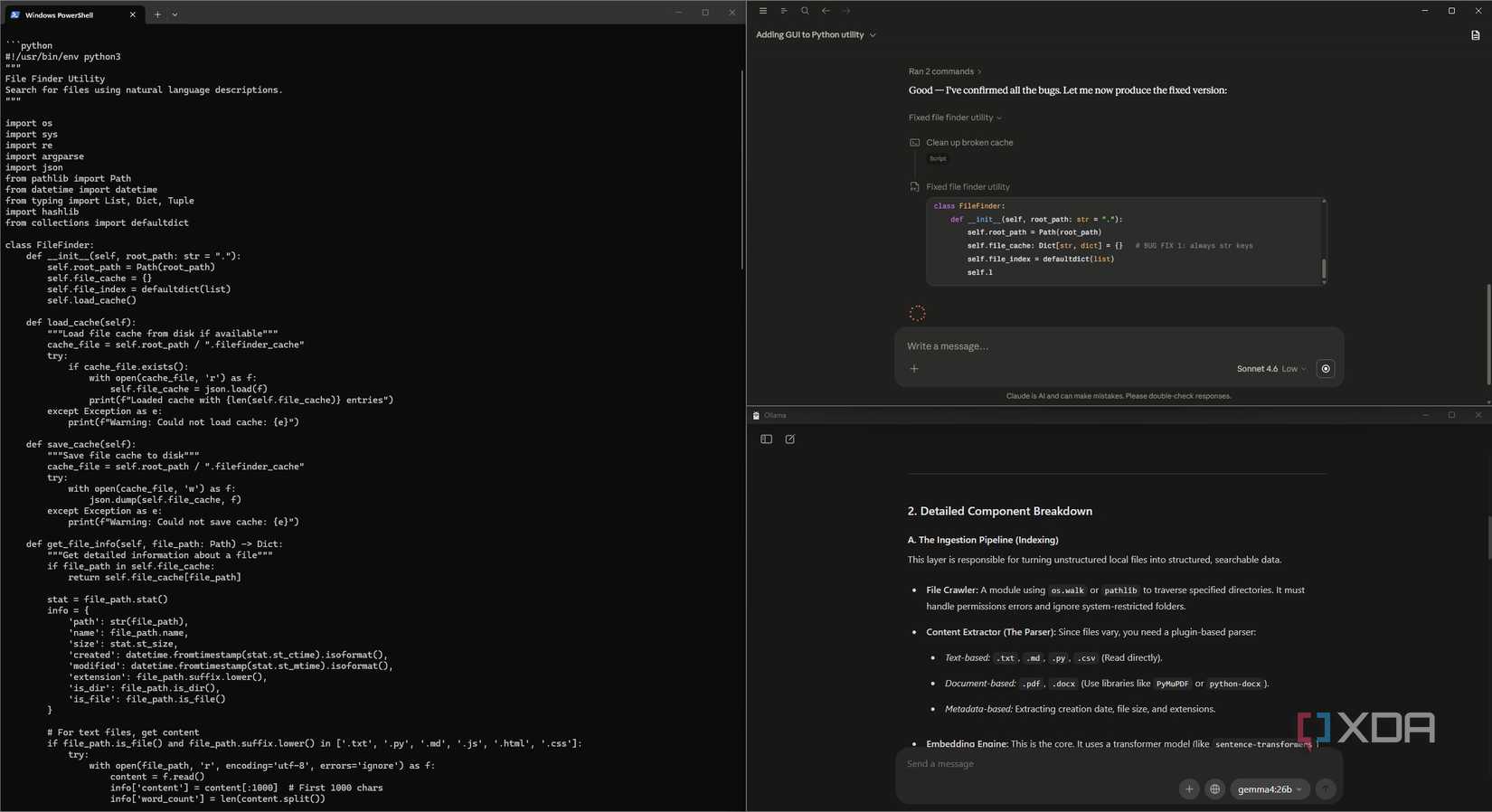
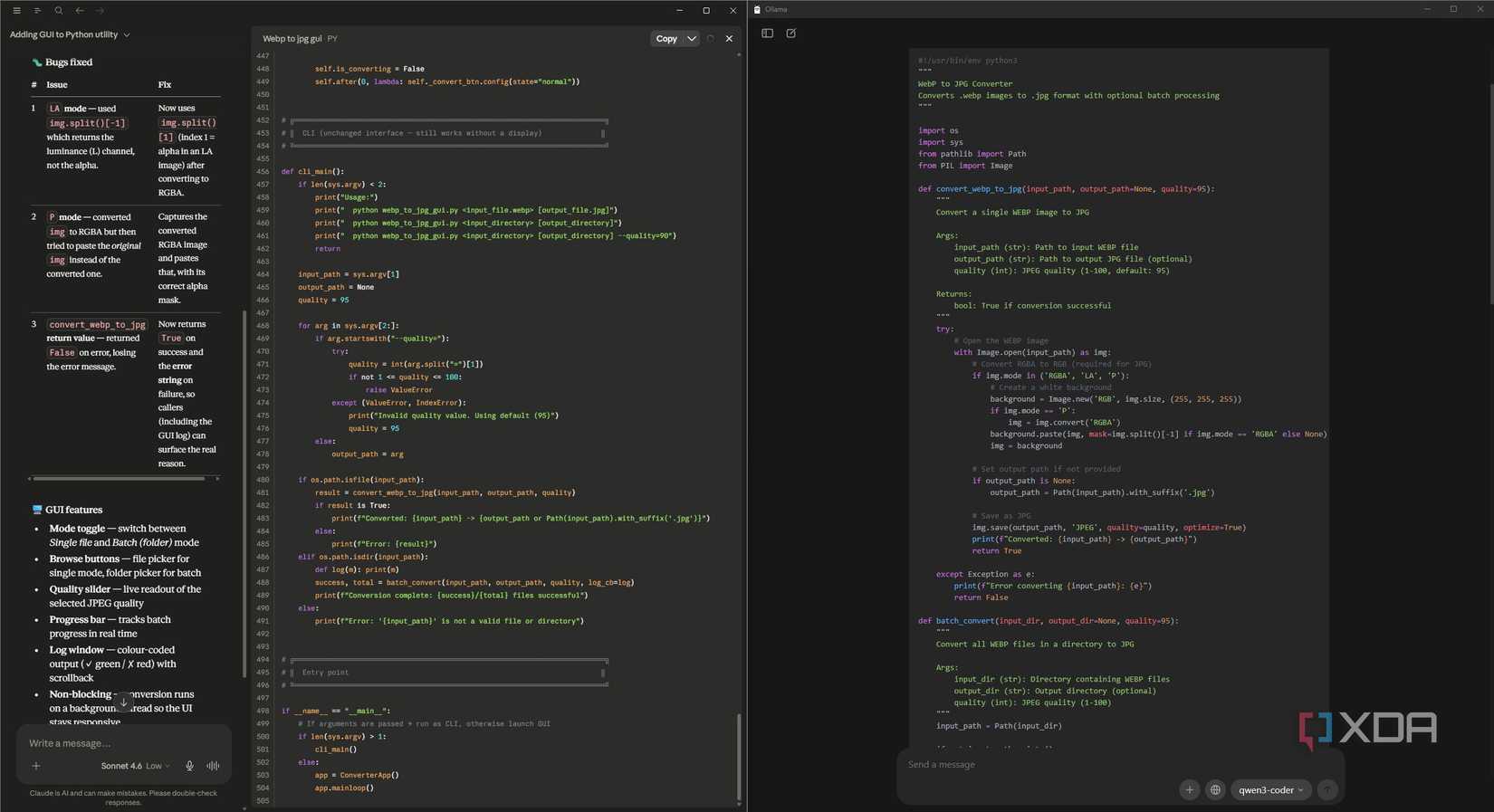
Qwen 3-Coder comes next, and enters the project in the iterative phase. This includes generating the code, adding features, testing, and debugging. This is precisely where the back-and-forth happens, and it’s also the kind of workload that used to drain my 5-hour limit on Claude. Qwen handles it locally, and the fact that it runs on the same Ollama interface as Gemma 4 means the transition between the two is as seamless as switching gears in a car you’re driving.
Claude enters the workflow at the very end as a “quality assurance” layer, and quite deliberately so, given its role in the workflow. Once the project is functional and needs a final pass, GUI enhancements, fixing a particularly stubborn bug that Qwen can’t handle, or has a feature that could benefit from interactive visuals, it’s time to use the reserved tokens on Claude.
The most common pushback I’ve received when detailing this approach is the fact that it demands capable hardware, and that’s quite fair. Running Qwen-3 Coder 30B and Gemma 4 locally means you will, at the very least, require 16GB of VRAM to keep the generation speeds comfortable. While the models are free to run, the GPU isn’t, and that’s a cost that’s worth accounting for.
There’s also a pertinent question of context-transfer. For smaller, lightweight utilities, passing the baton between the three models is seamless, but as a codebase swells, each handoff means losing the conversational history and context that kept the momentum of the project growing. I’ve found that keeping a running project brief in a text file is beneficial for mitigating it, but that’s also an extra step the workflow demands.
Another common critique is that the use of three models together is effectively overkill when Gemma 4 24B can handle light coding on its own. On some projects, it certainly is, and not every session will warrant the use of all three models at the same time. But when a coding task benefits from a purpose-built model, the difference in output quality between Qwen and Gemma handling the prompt is noticeable enough to justify the switch, and having both models already downloaded on the same interface means the cost of keeping that option available is effectively zero.