The topic I replaced cloud LLMs with local models running off a Proxmox LXC, and the… is currently the subject of lively discussion — readers and analysts are keeping a close eye on developments.
This is taking place in a dynamic environment: companies’ decisions and competitors’ reactions can quickly change the picture.
Whether it’s Perplexity’s reliable and transparent nature or Claude Code’s programming capabilities, there’s no denying that cloud-based large language models can be a godsend for productivity. Most cloud LLMs ship with beginner-friendly UIs, and the fact that you don’t have to put in extra work just to get them up and running makes them pretty convenient for the average user.
But I’ve spent the last couple of months moving away from cloud LLMs for my everyday tasks, partly since I don’t want external servers gaining access to my data, and also because I’d rather avoid the extra charges incurred by paid API usage. After migrating through a bunch of setups, I’ve honed in on a local LLM server running on my old Proxmox workstation, and it works surprisingly well for everything from simple prompting to OCR analysis, voice assistant inference backend, and automation pipelines.
Like most LLM-hosting enthusiasts, I started my journey by hosting local models on Ollama, and it served me well for the first couple of weeks. After all, pulling LLMs and deploying them is a piece of cake on Ollama, with a bunch of self-hosted apps supporting this inference engine natively. However, its extra performance overhead and lack of advanced tools became pretty apparent once I started looking into ways to maximize the efficiency on my local models. Once I started wanting to run bulky models (and I’ll go over them in a bit), it became clear that Ollama won’t work well for my needs, so I switched to llama.cpp instead.
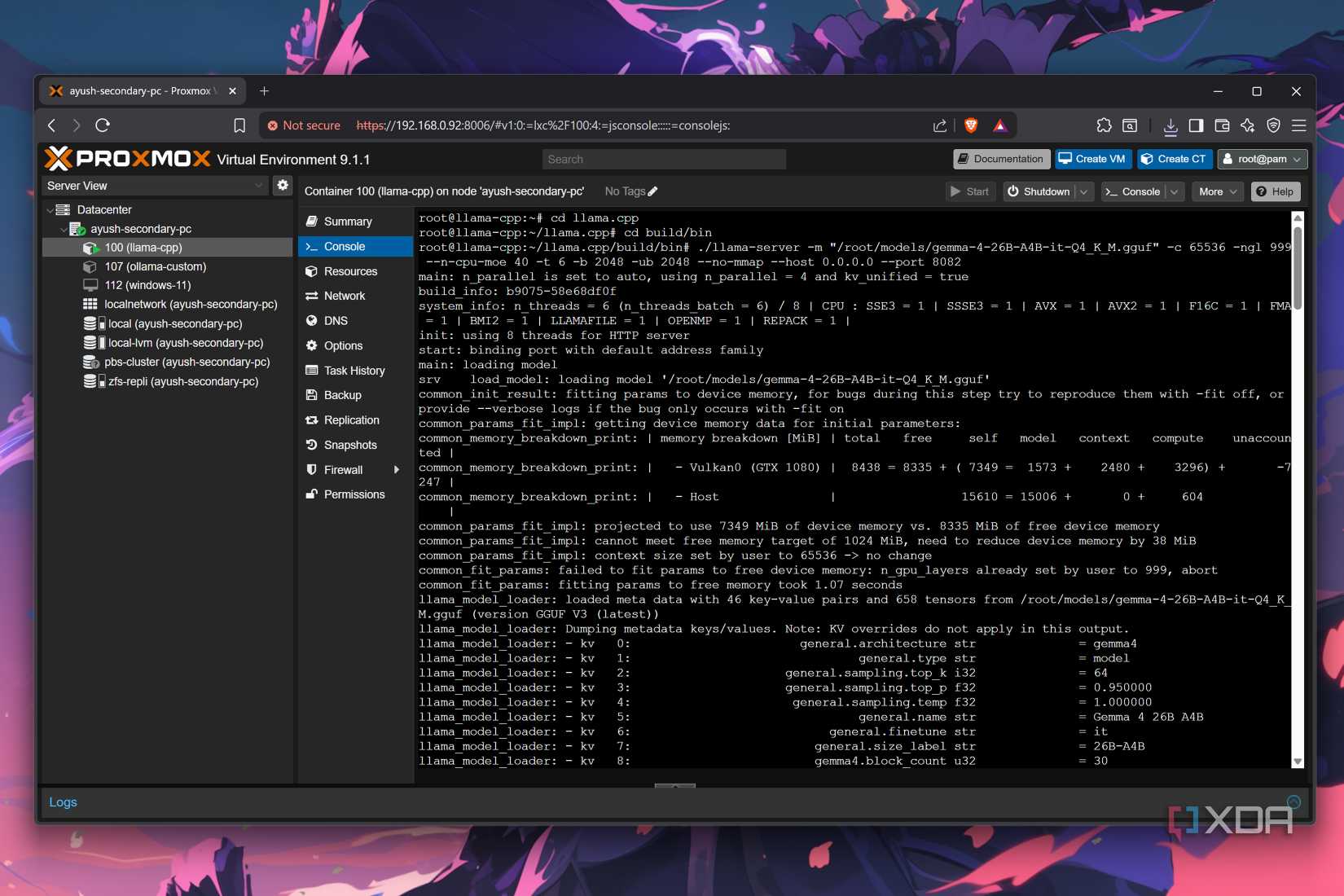
Rather, I began using the llama-server functionality to create an LLM server that remains operational 24/7 and hooks up to the rest of my FOSS arsenal thanks to its OpenAI-compatible API. I also went with a Proxmox LXC, as I can still share my old graphics card with Immich, Frigate, and other apps that need its computational prowess when my LLMs are inactive. Thanks to GPU passthrough, my llama-server LXC gets native-level performance, and I’ve upped its RAM resources all the way to 24GB (out of 32GB) to ensure it can fit MoE models (and I’ll go over them in a bit). On my aged system, I simply ran the ls -l /dev/nvidia* command to get the device IDs (195, 235, and 237 for my GPU), pasted the following syntax into the LXC’s config file, and installed the graphics card drivers inside the LXC to configure GPU passthrough, before compiling llama.cpp’s Vulkan variant.
During my Ollama days, I was starting to get frustrated by the accuracy (or rather, the lack thereof) of local models. Sure, 4B, 7B, and even 9B models could handle simple inference requests, but anything requiring detailed troubleshooting or complex reasoning would be too much for them to handle – and in some cases, they’d end up spouting complete nonsense. That’s when I started looking into bulkier models – LLMs that could crunch 20B+ parameters. But considering that my broke self only has a Pascal card (specifically, a GTX 1080), I couldn’t run conventional models without using the –ngl flag to offload entire layers from my GPU and causing the performance to plummet.
However, Mixture of Experts models let me offload the less frequently accessed resources onto my CPU and RAM, with the attention weights and other demanding units still remaining on my GPU. As such, I can host models like GPT-OSS-20B and Gemma4-26B-A4B on my VRAM-starved card at respectable token rates, with the latter even managing 15+ t/s with a fairly large context window.
As for their reasoning capabilities, I’d say they’re solid competitors to cloud models. While I still prefer the Qwen3.6-35B-A3B for hardcore coding tasks, Gemma4 is pretty effective at rewriting code, providing autosuggestions, and aiding my troubleshooting needs. Likewise, it has yet to hallucinate or provide irrelevant information when I use it for RAG analysis in Paperless AI, Open Notebook, and Blinko. While we’re on this subject…
Besides its terrific performance, llama-server also deploys an interface for accessing LLMs via a web browser – and it’s fairly useful for simple prompts and queries. It even supports MCP servers, and as long as I set the context window fairly high (and run the –webui-mcp-proxy flag), I have no issues controlling Obsidian, Home Assistant, TrueNAS, and a bunch of other apps via MCP tools on llama-server’s web interface.
However, I prefer Open WebUI for the majority of my tasks, and its ChatGPT-like interface makes it fairly accessible. But the real draw of Open WebUI is the sheer number of customization options and integrations that I can pair it (and by extension, my llama-server LLMs) with. There’s the open terminal facility, which lets me execute Python code on the browser, and connecting it with SearXNG lets my Gemma4 instance access websites on the Internet instead of relying solely on its trained knowledge base. It even supports ComfyUI, and I often use Open WebUI to trigger the upscaling workflows I’ve configured on the app.
I’ve been building my LLM pipelines for a couple of months, and it’s really mind-boggling how much you can accomplish with them. Once you venture past the 20B mark, the reasoning capabilities of self-hosted models skyrocket to the point where they’re good enough to replace their cloud counterparts for coding workloads. And with MoE models becoming more popular, it’s possible to run competent clankers without dealing with slow token generation rates on an old GPU or throwing thousands of bucks on a new system.