
The topic High availability doesn’t require matching servers — my three different mini… is currently the subject of lively discussion — readers and analysts are keeping a close eye on developments.
This is taking place in a dynamic environment: companies’ decisions and competitors’ reactions can quickly change the picture.
I didn’t build my Proxmox cluster the way most sane documentation would quietly prefer. Instead of buying three identical nodes with matching CPUs, memory, and network adapters, I used three different mini PCs that fit my budget, desk, and tolerance for fan noise. One is a small office box with more patience than power, one is a newer machine with a better CPU, and one is an oddball that I probably wouldn’t recommend unless you enjoy reading BIOS menus. On paper, it sounds like a recipe for a fragile home lab theater.
Failover doesn’t need to be perfect to be useful, especially in a home lab where recovery matters more than pretending it’s a data center.
But that’s exactly why I wanted to try it. High availability often gets presented as something that belongs to neat racks, identical servers, and diagrams with expensive-looking arrows. Proxmox doesn’t require that level of ceremony, and my uneven little cluster proved it in a surprisingly practical way. The real win isn’t that every workload survives every failure perfectly, but that a mixed mini PC cluster can still provide meaningful resilience if you plan around its limits.
A Proxmox cluster may not be all that useful for most tinkerers, but it was a fantastic addition to my home lab
The first thing I learned is that Proxmox doesn’t demand hardware symmetry before it lets high availability function. It requires a quorum, shared or replicated storage, compatible virtual machine settings, and sufficient resources on another node to restart the workload. That sounds obvious, but it matters when you’re building from second-hand mini PCs instead of a shopping cart full of matching machines. The cluster doesn’t care that one node looks more professional than the others.
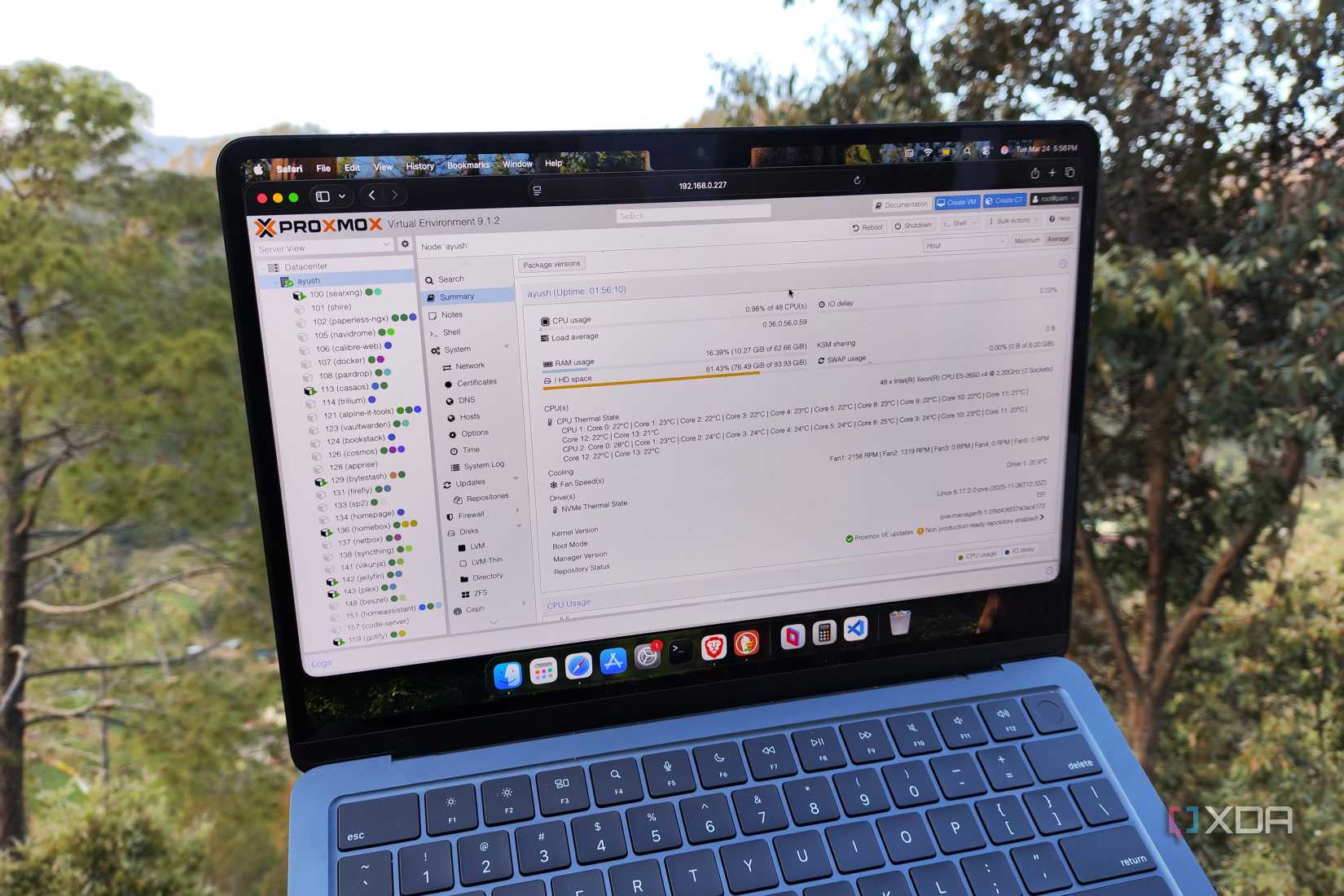
Proxmox high availability works best when you size workloads for the weakest node, not the strongest one. Mismatched hardware can still fail over properly, but only if the destination node has enough CPU, memory, storage access, and network configuration to run the affected VM safely.
That doesn’t mean hardware differences disappear. CPU generation matters if you use host-specific CPU types, and memory limits can quickly decide where a VM is allowed to land. Network interfaces can also lead to uneven results if one machine has 2.5 GbE while another is stuck on gigabit. Still, these are planning problems, not automatic deal-breakers.
The trick is to design for the weakest node rather than the strongest one. I stopped thinking of the cluster as three equal servers and started treating it as a resource pool with personalities. Smaller VMs have greater placement flexibility, while heavier services require stricter rules. Once I accepted that, high availability became much less mysterious and much more useful.
The most important part of my setup wasn’t the mini PCs themselves. It was the dull work around storage, networking, and VM configuration. High availability can only restart a VM on another node if the required disks and networks make sense from that other node’s perspective. A mismatched cluster can tolerate different hardware, but it won’t forgive sloppy assumptions.
For my needs, the safest approach was to keep workloads small and make storage decisions deliberately. Some services were good candidates for replication because they didn’t change frequently and didn’t require large disks. Others were better handled with backups and manual recovery because pretending they were HA-ready would only create false confidence. That distinction helped me avoid turning Proxmox HA into a magic button.
The actual failover test was both dramatic and deeply undramatic. I powered down a node, watched the cluster notice the problem, and waited while the affected VM restarted elsewhere. It wasn’t instant, and it wasn’t invisible, but it worked. For a home lab running on three different mini PCs, that result felt far more valuable than chasing a flawless enterprise impression.
The drawback is simple: different mini PCs make the cluster harder to maintain. When all nodes are identical, capacity planning is cleaner, troubleshooting is calmer, and every migration feels less conditional. With my setup, I need to remember which node has more RAM, which has the better CPU, and which machine to avoid hosting certain workloads on. That’s not difficult every day, but it adds mental overhead.
Performance after failover can also vary in ways that matter. A VM that feels snappy on the strongest node may feel cramped on the weakest one, especially if other services are already running there. High availability only answers whether the service can come back up somewhere else. It doesn’t guarantee that the new home will feel just as fast.
There’s also the issue of trust. A mixed cluster made from small consumer or office PCs won’t have the same redundancy story as proper server hardware. Power supplies, cooling, firmware behavior, and network adapters can all behave differently under stress. Proxmox can coordinate the recovery, but it can’t make every little box equally dependable.
Even with those drawbacks, I still think the mixed mini PC cluster is worth it. The point isn’t to copy a data center with cheaper hardware. It’s to make a home lab more tolerant of maintenance, mistakes, and ordinary hardware failures. In that context, “good enough to restart elsewhere” is a meaningful upgrade over “everything is down until I fix one box.”
The uneven hardware also forced better habits. I had to think carefully about VM sizing, backup strategy, storage layout, and which services deserved HA in the first place. That made the cluster healthier than it would have been if I had simply thrown identical hardware at the problem and assumed the design was solid. Constraints can be annoying, but they quickly expose lazy architecture.
I also like that this setup keeps the barrier to entry low. Plenty of people have access to used mini PCs, retired office machines, or small systems that are still perfectly useful. Proxmox turns that hardware into something more capable than a pile of separate boxes. You still need to test, document, and respect the limits, but you don’t need a pristine rack to learn serious infrastructure lessons.
My three-node Proxmox setup is not elegant, and I wouldn’t pretend otherwise. It has quirks, uneven capacity, and a few decisions I’d change if I were starting again. But the core experiment succeeded: high availability failover worked across three completely different mini PCs. More importantly, it worked because the cluster was planned around real limitations instead of wishful thinking.
That’s the lesson I’d take from this build. Proxmox HA isn’t reserved for identical nodes or enterprise-grade gear, but it also isn’t a magic spell that makes any hardware combination reliable. A mixed mini PC cluster can be genuinely useful when workloads are sized carefully, storage is handled sensibly, and failover is tested before it’s needed. It won’t make a home lab invincible, but it can make it far less fragile.
Even if your Proxmox nodes aren’t on identical hardware, you can still take advantage of high availability.